JPA를 활용하여 병원 검색과 리뷰 검색을 구현해 봤다. 테이블 관계는 아래와 같다.

where 절의 like를 사용하여 진료 과목, 병원 이름, 태그를 검색하게 했고, JMeter를 통해 성능 테스트를 했다.
JMeter의 조건은 아래와 같다.
- Number of Threads (users) : Thread의 수(가상 사용자)
- Ramp-up period (seconds) : 요청 주기(초)
- Loop Count : 테스트를 반복하는 횟수
- Infinite - 무한대로 호출
100명의 사용자가 1초에 3번씩 요청을 하게 설정했다.
1. 엔티티를 DTO로 변환 및 한계 돌파
컬렉션을 fetch join하면 페이징이 불가능하고, 일대다 조인이 발생하므로 데이터가 예측할 수 없을 정도로 증가한다. 또한 중복 데이터가 엄청 많아져서 데이터가 뻥튀기된다.
이에 아래와 같은 방식을 적용하였다.
- ToOne 관계를 모두 fetch join. ToOne 관계는 row 수를 증가시키지 않기에 페이징 쿼리에 영향을 주지 않는다.
- 컬렉션 관계는 모두 지연으로 조회.
- 지연 로딩 성능 최적화를 위해 hibernate.default_batch_fetch_join 적용.
public Page<Hospital> searchHospitalVer2(String searchName, Pageable pageable){
QueryResults<Hospital> result = queryFactory
.selectFrom(hospital)
.leftJoin(hospital.detailedHosInformation,detailedHosInformation).fetchJoin()
.leftJoin(hospital.hospitalThumbnail,hospitalThumbnail).fetchJoin()
.where((hospitalNameLike(searchName)
.or(hospitalSubjectLike(searchName)
.or(tagNameLike(searchName)
))))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetchResults();
List<Hospital> content = result.getResults();
long total = result.getTotal();
return new PageImpl<>(content, pageable, total);
}
private BooleanExpression hospitalNameLike(String name) {
return isEmpty(name) ? null : hospital.hospitalName.contains(name);
}
private BooleanExpression hospitalSubjectLike(String name) {
return isEmpty(name) ? null : hospital.medicalSubjectInformation.contains(name);
}
private BooleanExpression tagNameLike(String name) {
return isEmpty(name) ? null : hospital.postTags.any().tag.name.eq(name);
}ToOne 관계에 있는 detailedHosInformation 객체와 hospitalThumbnail 객체를 fetchJoin 하였다. (쿼리 1번)
ToMany 관계에 있는 컬렉션 부분은 hibernate.default_batch_fetch_join 옵션을 사용하면 컬렉션이나 프록시 객체를 한꺼번에 size만큼 in 쿼리로 조회한다.
이 옵션은 size를 설정하면 컬렉션을 size만큼 in 쿼리로 한 번에 다 가져온다는 설정이다. 보통 100~1000으로 설정한다.
1000 이상으로 잡으면 한 번에 1000개를 DB에서 애플리케이션으로 불러와서 DB에 순간 부하가 증가할 수 있기에 보통 1000 이하로 설정한다.
필자는 500으로 설정했고, 만약 컬렉션의 총데이터가 5000개라면 500개의 단위만큼 10번 in 쿼리를 날린다.
public class HospitalSearchListsVer2Response {
private Long hospitalId;
private String hospitalName;
private String imageKey;
private BusinessCondition businessCondition;
private String medicalSubjectInformation;
private String roadBaseAddress;
private List<PostTagVer2DTO> postTagVer2DTOS;
private List<ReviewHospitalVer2DTO> reviewHospitalVer2DTOS;
public static HospitalSearchListsVer2Response from(Hospital hospital) {
return HospitalSearchListsVer2Response
.builder()
.hospitalId(hospital.getId())
.hospitalName(hospital.getHospitalName())
.imageKey(null)
.businessCondition(hospital.getBusinessCondition())
.medicalSubjectInformation(hospital.getMedicalSubjectInformation())
.roadBaseAddress(hospital.getDetailedHosInformation().getHospitalAddress()
.getRoadBaseAddress())
.postTagVer2DTOS(hospital.getPostTags().stream()
.map(postTag -> new PostTagVer2DTO(postTag))
.collect(Collectors.toList()))
.reviewHospitalVer2DTOS(hospital.getReviewHospitals().stream()
.map(reviewHospital -> new ReviewHospitalVer2DTO(reviewHospital))
.collect(Collectors.toList()))
.build();
}DTO의 코드는 위와 같다.
ToMany 관계에 있는 PostTagVer2DTO와 ReviewHospitalVer2DTO를 각각 1번씩 호출한다. (1+1)
※ 만약 각각의 컬렉션 데이터 크기가 500이 넘어간다면 500단위만큼 in 쿼리를 호출할 것이다.
이러면 총 쿼리 회수가 3회가 됐다.(1+1+1)
성능 결과는 아래와 같다.
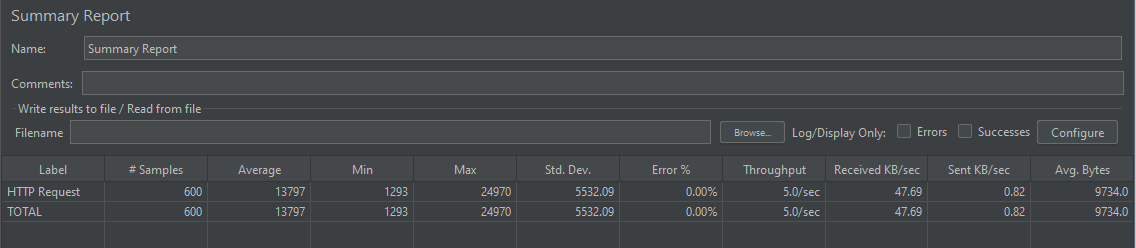
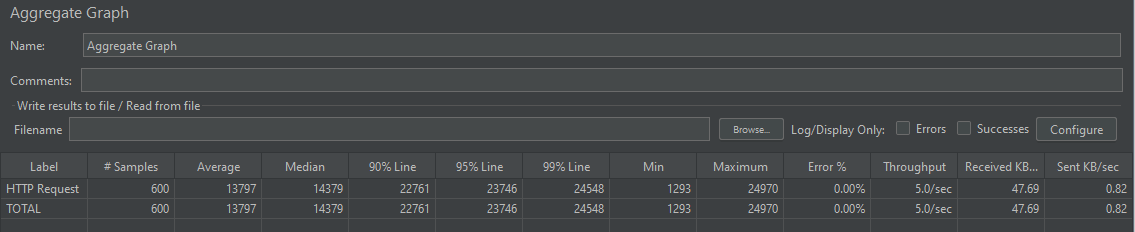
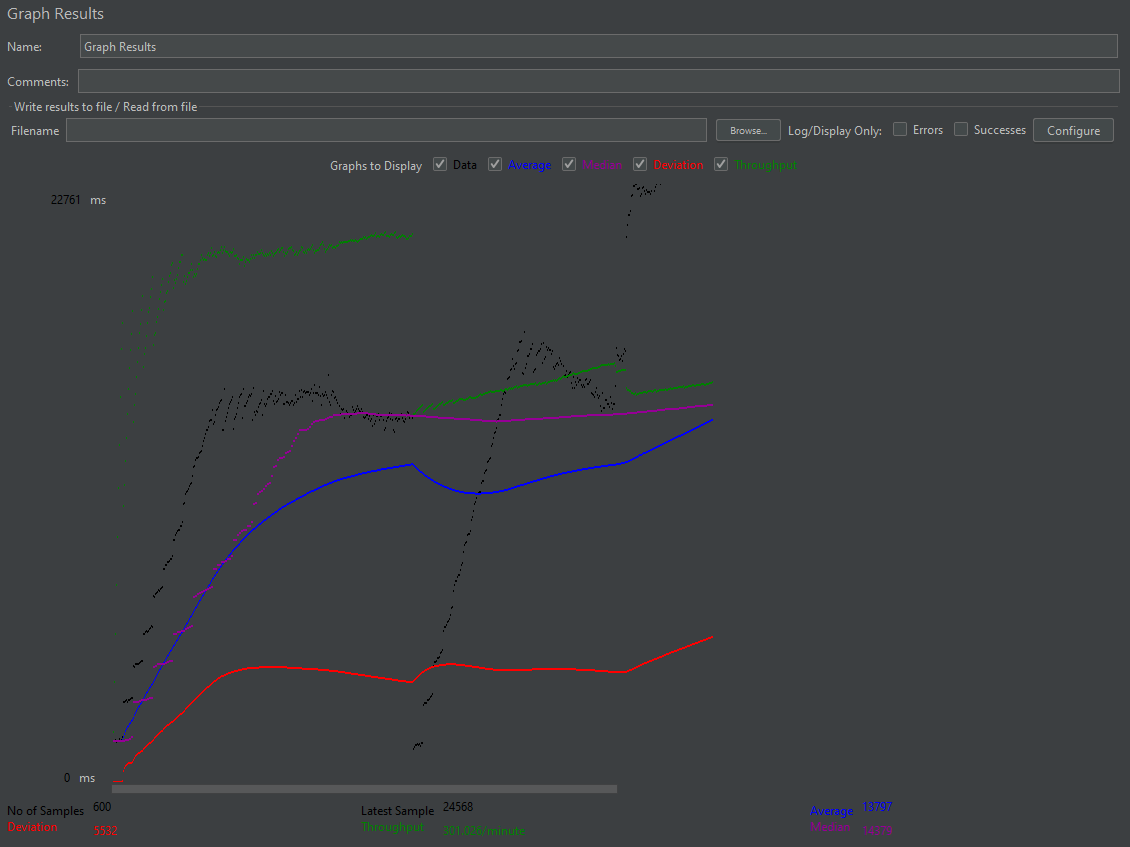
2. DTO 직접 조회
public Page<HospitalSearchDto> searchHospitalVer1(String searchName, Pageable pageable) {
Page<HospitalSearchDto> result = findHospital(searchName, pageable);
(중략)
return result;
}
private Page<HospitalSearchDto> findHospital(String searchName, Pageable pageable) {
List<HospitalSearchDto> content = queryFactory
.select(new QHospitalSearchDto(hospital.id,
hospital.hospitalName,
hospitalThumbnail.imageKey,
hospital.businessCondition,
hospital.medicalSubjectInformation,
detailedHosInformation.hospitalAddress.roadBaseAddress
)
)
.from(hospital)
.leftJoin(hospital.detailedHosInformation, detailedHosInformation)
.leftJoin(hospital.hospitalThumbnail, hospitalThumbnail)
.where((hospitalNameLike(searchName)
.or(hospitalSubjectLike(searchName)
.or(tagNameLike(searchName))))
)
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
//쿼리 수 세기
JPAQuery<Hospital> countQuery = queryFactory
.select(hospital)
.from(hospital)
.join(hospital.detailedHosInformation, detailedHosInformation)
.where((hospitalNameLike(searchName)
.or(hospitalSubjectLike(searchName)
.or(tagNameLike(searchName)
))));
return PageableExecutionUtils.getPage(content, pageable, () -> countQuery.fetchCount());
}1번 방식과 다른점은 Hospital가 아닌 DTO를 return 한다는 점이다.
@Data
public class HospitalSearchDto {
private Long hospitalId;
private String hospitalName;
private String imageKey;
private BusinessCondition businessCondition;
private String medicalSubjectInformation;
private String roadBaseAddress;
private List<PostTagDto> postTagDtos;
private List<ReviewHospitalDto> reviewHospitals;
@QueryProjection
public HospitalSearchDto(Long hospitalId, String hospitalName, String imageKey,
BusinessCondition businessCondition,
String medicalSubjectInformation,
String roadBaseAddress) {
this.hospitalId = hospitalId;
this.hospitalName = hospitalName;
this.imageKey = imageKey;
this.businessCondition = businessCondition;
this.medicalSubjectInformation = medicalSubjectInformation;
this.roadBaseAddress = roadBaseAddress;
}
}QueryDSL의 @QueryProjection을 활용하여 entity 전체를 select 하는 게 아닌, 원하는 부분만 select 하게 만들었다. 이러면 select 양이 많이 줄어든다.
public Page<HospitalSearchDto> searchHospitalVer1(String searchName, Pageable pageable) {
Page<HospitalSearchDto> result = findHospital(searchName, pageable);
result.forEach(hospital -> {
List<ReviewHospitalDto> reviewHospitals =
findReviewHospitals(hospital.getHospitalId());
hospital.setReviewHospitals(reviewHospitals);
});
result.forEach(hospital -> {
List<PostTagDto> postTags =
findPostTags(hospital.getHospitalId());
hospital.setPostTagDtos(postTags);
});
return result;
}
private List<ReviewHospitalDto> findReviewHospitals(Long hospitalId){
return queryFactory
.select(new QReviewHospitalDto(reviewHospital.hospital.id,
reviewHospital.evCriteria.averageRate.avg(),
reviewHospital.count()))
.from(reviewHospital)
.join(reviewHospital.hospital, hospital)
.groupBy(reviewHospital.hospital.id)
.where(reviewHospital.hospital.id.eq(hospitalId))
.fetch();
}
private List<PostTagDto> findPostTags(Long hospitalId){
return queryFactory
.select(new QPostTagDto(postTag.hospital.id, tag.id, tag.name))
.from(postTag)
.join(postTag.tag, tag)
.where(postTag.hospital.id.eq(hospitalId))
.fetch();
}컬렉션의 데이터는 forEach로 각각 넣어줬다.
이러면 1번의 방식보다 확실히 select양이 많이 줄어들지만, 최초 쿼리 1번 컬렉션은 각각 N번씩 실행된다.
총 쿼리 회수가 1+N+M이 발생한 셈이다.
성능 결과는 아래와 같다.
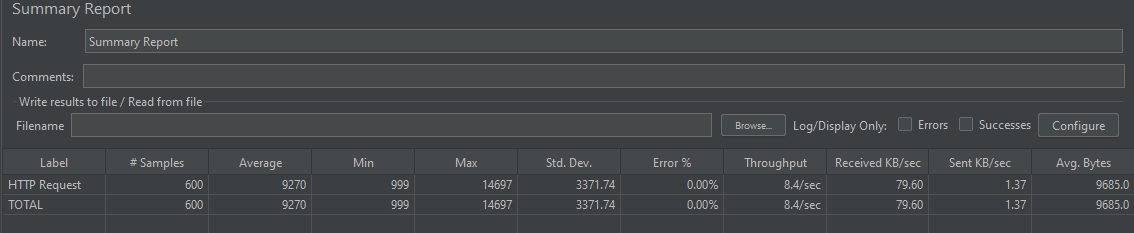

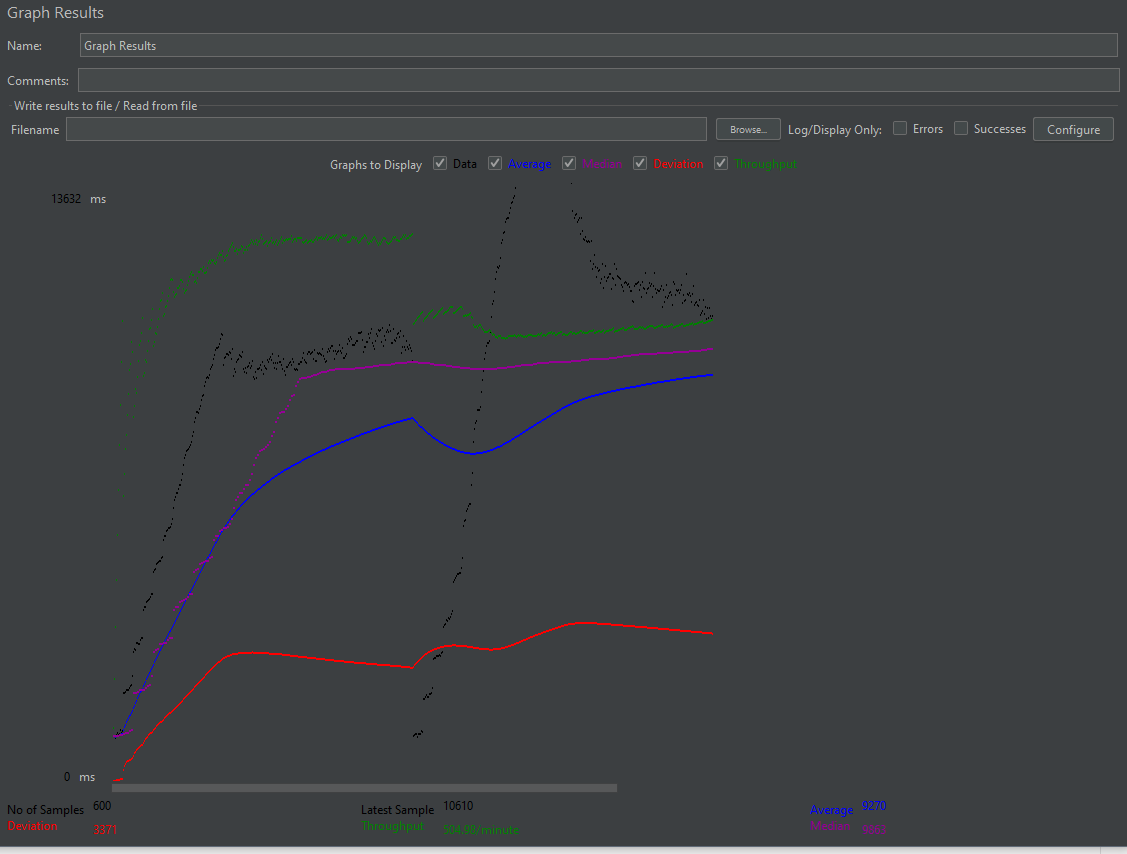
3. DTO 직접 조회 및 컬렉션 최적화
2번의 방식과 동일하나, 컬렉션을 최적화한 방식이다.
public Page<HospitalSearchDto> searchHospital(String searchName, Pageable pageable) {
Page<HospitalSearchDto> result = findHospitals(searchName, pageable);
//비어있으면 바로 반환.
if (result.getContent().isEmpty()) {
return result;
}
//병원 id 모음.
List<Long> hospitalIds = result.stream()
.map(h -> h.getHospitalId())
.collect(Collectors.toList());
(중략)
return result;
}먼저 stream의 map을 통해 병원 id의 list를 뽑아낸다.
public Page<HospitalSearchDto> searchHospital(String searchName, Pageable pageable) {
Page<HospitalSearchDto> result = findHospitals(searchName, pageable);
//병원 id 모음.
List<Long> hospitalIds = result.stream()
.map(h -> h.getHospitalId())
.collect(Collectors.toList());
//리뷰 넣기
List<ReviewHospitalDto> reviewHospitalDtos =
queryFactory
.select(new QReviewHospitalDto(reviewHospital.hospital.id,
reviewHospital.evCriteria.averageRate.avg(),
reviewHospital.count()))
.from(reviewHospital)
.join(reviewHospital.hospital, hospital)
.groupBy(reviewHospital.hospital.id)
.where(reviewHospital.hospital.id.in(hospitalIds))
.fetch();
return result;
}그리고 ReviewHospitalDTO의 where 절에서 hospital의 id를 in 절로 넣어버린다.
(예시) .where(reviewHospital.hospital.id.in(hospitalIds))
Map<Long, List<ReviewHospitalDto>> reviewHospitalMap = reviewHospitalDtos.stream()
.collect(Collectors
.groupingBy(reviewHospitalDto -> reviewHospitalDto.getHospitalId()));
result.forEach(h -> h.setReviewHospitals(reviewHospitalMap.get(h.getHospitalId())));성능을 더 최적화하기 위해서 reviewHospitalDTO를 Map으로 바꿔준다.
key는 hospital의 id이고, values는 List<ReviewHospitalDTO>이다.
forEach로 기존 hospital 쿼리의 결과에 ReviewHospital를 더해준다.
2번 방식은 루프를 돌릴 때마다 쿼리를 날렸지만, 3번 방식은 쿼리를 한번 날리고 메모리에서 Map을 다 가져온 다음에 매칭해서 세팅을 해준다. (매칭 성능 O(1))
이러면 쿼리가 1+1이 나온다. 필자는 컬렉션인 ReviewHospital와 PostTag를 호출하였다.
최종 코드는 아래와 같다.
public Page<HospitalSearchDto> searchHospital(String searchName, Pageable pageable) {
Page<HospitalSearchDto> result = findHospitals(searchName, pageable);
//비어있으면 바로 반환.
if (result.getContent().isEmpty()) {
return result;
}
//병원 id 모음.
List<Long> hospitalIds = result.stream()
.map(h -> h.getHospitalId())
.collect(Collectors.toList());
//리뷰 넣기
List<ReviewHospitalDto> reviewHospitalDtos =
queryFactory
.select(new QReviewHospitalDto(reviewHospital.hospital.id,
reviewHospital.evCriteria.averageRate.avg(),
reviewHospital.count()))
.from(reviewHospital)
.join(reviewHospital.hospital, hospital)
.groupBy(reviewHospital.hospital.id)
.where(reviewHospital.hospital.id.in(hospitalIds))
.fetch();
Map<Long, List<ReviewHospitalDto>> reviewHospitalMap = reviewHospitalDtos.stream()
.collect(Collectors
.groupingBy(reviewHospitalDto -> reviewHospitalDto.getHospitalId()));
result.forEach(h -> h.setReviewHospitals(reviewHospitalMap.get(h.getHospitalId())));
//태그 넣기
List<PostTagDto> postTagDtos =
queryFactory
.select(new QPostTagDto(postTag.hospital.id, tag.id, tag.name))
.from(postTag)
.join(postTag.tag, tag)
.where(postTag.hospital.id.in(hospitalIds))
.fetch();
Map<Long, List<PostTagDto>> tagHospitalMap = postTagDtos.stream()
.collect(Collectors.groupingBy(PostTagDto -> PostTagDto.getHospitalId()));
result.forEach(h -> h.setPostTagDtos(tagHospitalMap.get(h.getHospitalId())));
return result;
}1, 2번 방식과 비교해 보면 select양이 확연히 줄어들고, 쿼리 호출 회수가 총 1+1+1밖에 안 된다.
성능 테스트 결과는 아래와 같다.
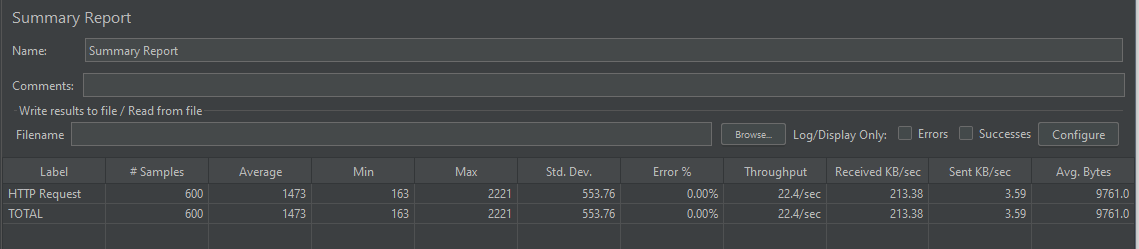
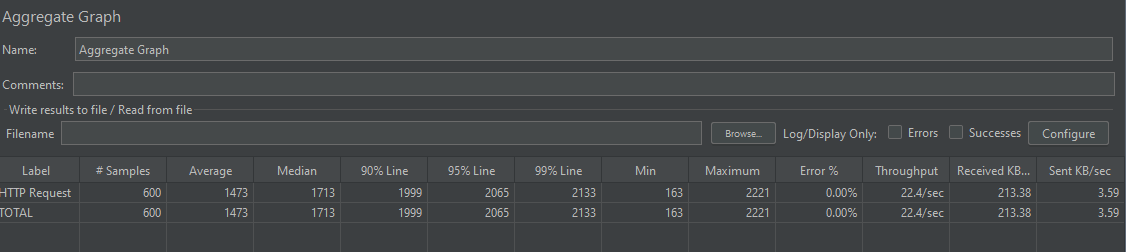
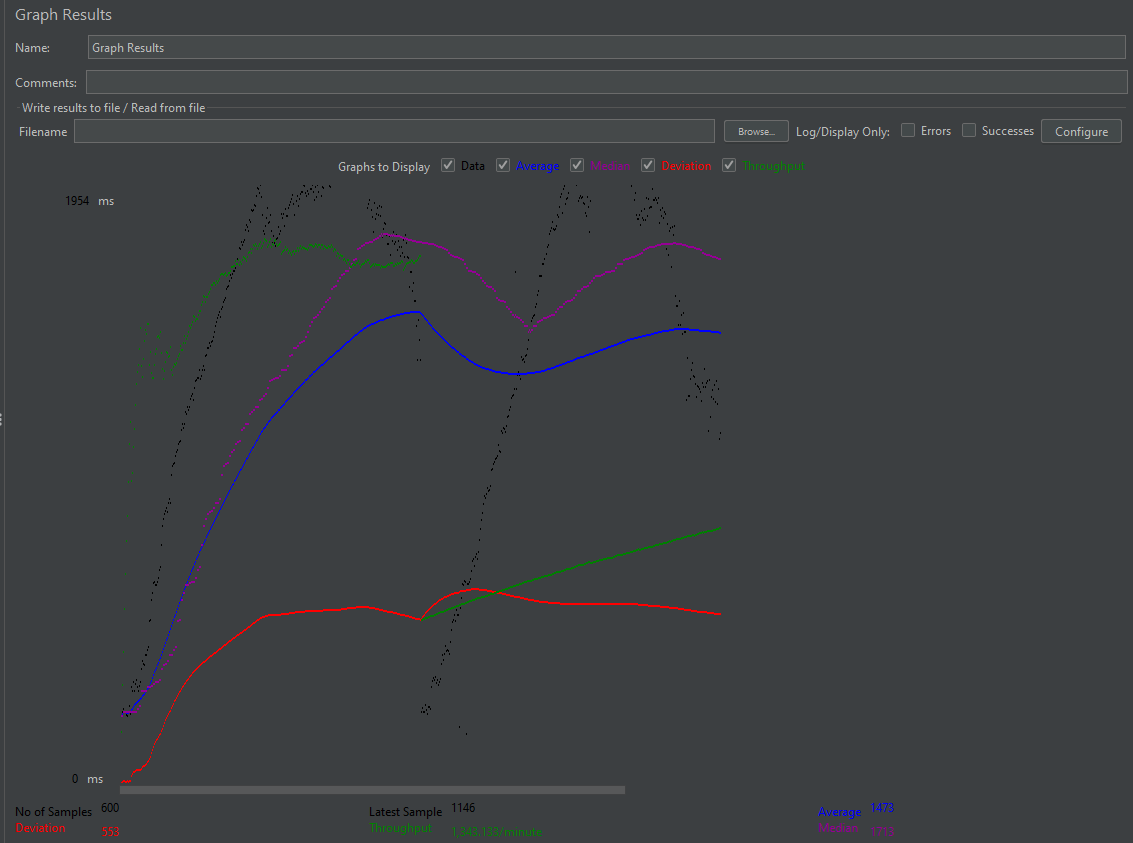
1, 2번 방식과 비교해보면 성능이 확연히 증가한 걸 알 수 있다.
4. 인덱스 적용
그러면 인덱스를 적용해보면 조회 성능이 빨라질까?
시간이 좀 지난 후에 궁금해서 테스트를 해봤더니.

기존 3번 방식으로 테스트를 했을 때는 위의 성능 테스트가 나왔다.
@Entity
@Getter
@Table(indexes = @Index(name="idx__subject__hospitalname",columnList = "medicalSubjectInformation,hospitalName"))
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Hospital extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "hospital_id")
private Long id;
@OneToMany(mappedBy = "hospital")
private List<Estimation> estimations = new ArrayList<>();
@OneToMany(mappedBy = "hospital")
private List<PostTag> postTags = new ArrayList<>();
@OneToMany(mappedBy = "hospital")
private List<Bookmark> bookmarks = new ArrayList<>();
@OneToMany(mappedBy = "hospital")
private List<Question> questions = new ArrayList<>();
@OneToMany(mappedBy = "hospital")
private List<ReviewHospital> reviewHospitals = new ArrayList<>();
@OneToMany(mappedBy = "hospital")
private List<HospitalImage> hospitalImages = new ArrayList<>();
@OneToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "staffHosInformation_id")
private StaffHosInformation staffHosInformation;
@OneToOne(cascade = CascadeType.ALL, fetch = FetchType.LAZY)
@JoinColumn(name = "detailedHosInformation_id")
private DetailedHosInformation detailedHosInformation;
@OneToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "hospitalThumbnail_id")
private HospitalThumbnail hospitalThumbnail;
@NotNull
private String licensingDate;
@NotNull
private String hospitalName;
@NotNull
private String phoneNumber;
@NotNull
private String distinguishedName;
@NotNull
private String medicalSubjectInformation;
@NotNull
private String cityName;
@Enumerated(EnumType.STRING)
@NotNull
private BusinessCondition businessCondition;
}hospital Entity에는 위의 코드처럼 진료 과목과 병원 이름을 복합 인덱스로 지정했고, Tag Entity에서는 태그 이름을 단일 인덱스로 설정하였다.
그리고 인덱스를 지정한 DB에 성능 테스트를 해봤더니


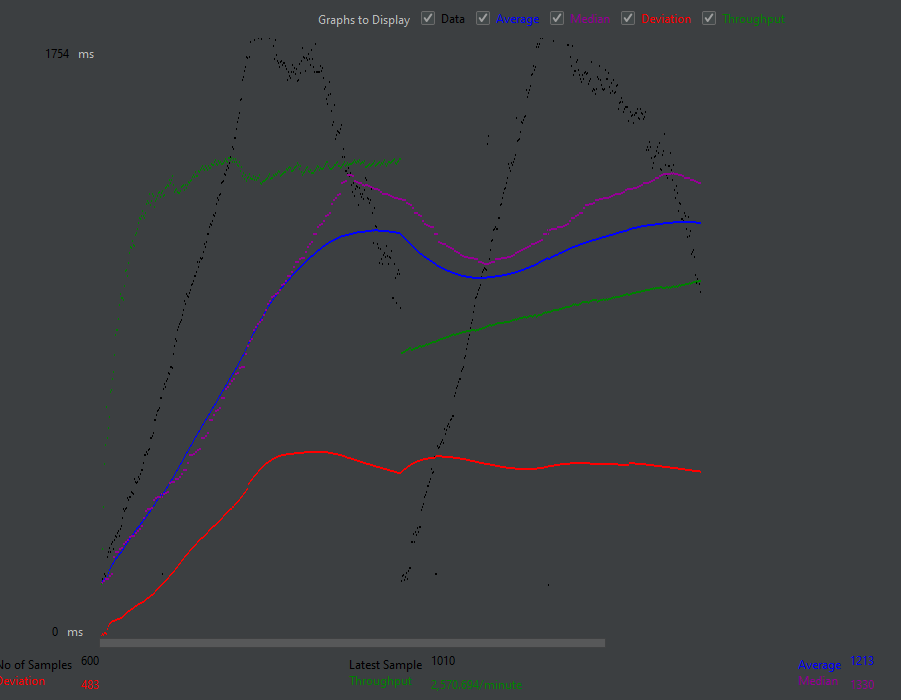
3번 방식보다 오히려 성능이 내려가거나, 비슷한 것이었다.
테스트를 할 때마다 약간의 성능차이가 있으니 이 정도 차이는 오차범위 안이라 생각된다. 즉 인덱스를 적용하나, 안 하나 별 차이가 없는 것이다.
왜 그러는 걸까?
인덱스의 자료구조는 B-Tree이다. 인덱스를 걸면 아래처럼 시작 값으로 데이터를 조회한다.
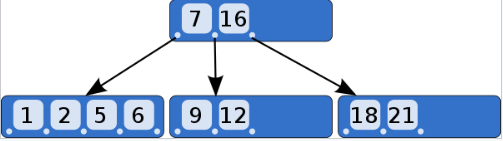
그렇기에 포함되는 단어(%찾는 단어%) 혹은 끝나는 단어(%찾는 단어)의 경우 기준을 잡을 수 없기에 full-scan으로 검색하게 된다.
나는 where 절에서 '%단어%' like로 검색했기에 full-scan으로 검색돼서, index를 적용해도 성능이 별차이가 없던 것이다.
정리하면 like 쿼리에서 '%'가 앞에 붙어있다면, index의 순차탐색이 불가능하다.
만약 like절로도 index를 타고 싶게 만들라면 아래처럼
where name like '찾는 단어%'%를 뒤에 붙여야 한다.
5. 결론
2번 방식은 1+N 호출 때문에 1번 방식이 빠를 줄 알았지만, 2번 방식이 오히려 빨라서 당황했었다. 추정컨대 N개의 Entity를 호출하니 select 양이 확실히 많았었고, 내가 세팅한 컬렉션의 데이터 수가 적기에 이런 결과가 나온 걸로 추정해 본다.
그러나 EC2 환경에서 Nginx로 배포로 해봤더니 2 <1 <3 순으로 성능이 정상적으로 나온 걸 확인할 수 있었다.
1번 방식

2번 방식
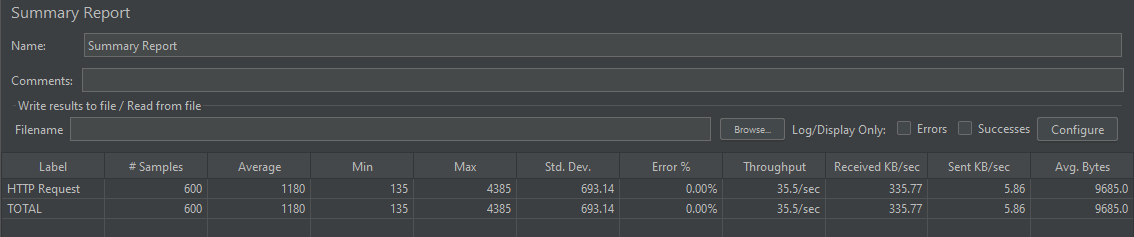
3번 방식
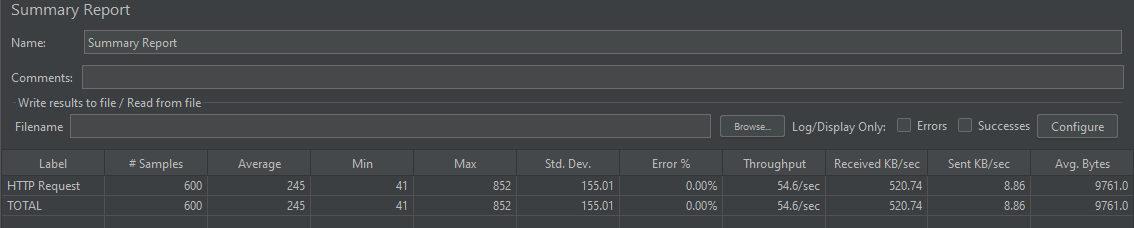
확실히 기존 localhost에서 측정한 것보다 성능이 확연히 증가했으며, 이는 Nginx가 고성능 웹서버라서 성능이 확연히 좋아진 걸로 추정된다. 실제로 Nginx가 Apache랑 비교했을 때 동적 콘텐츠의 성능은 비슷할지 몰라도, 정적 컨텐츠의 경우 벤치마크 테스트 시 2.5배 빠른 성능을 보이긴 했다. 정적 컨텐츠를 서비스하는 경우 동시 접속이나 대용량 서비스 처리면에서 Nginx가 우수한 것이다.
TPS는 아쉽기는 하나 EC2가 T2.micro임을 고려해 보면 적절하게 나왔다 생각한다.
3번 방식이 성능이 확실히 우수하기는 하나, 재사용성이 떨어진다는 치명적인 단점이 있다. 자세한 내용은 이 글을 참고하길 바란다.
결론: 처음 개발을 할 때에는 유지보수를 위해 범용성을 먼저 생각해서 1번 방식으로 개발하고, 이후 성능 테스트나 서비스 지표등을 보고 3번 방식을 고려해 보는 게 좋다고 생각한다.
6. 이게 최선일까?
1, 2, 3, 4 번 방식 모두 where 절에 like를 사용하였다. 이러면 치명적인 단점이 생긴다. like를 사용하면 오버헤드가 엄청 증가하기에 검색이 매우 느려진다. 4번 인덱스 방식으로도 성능을 못 잡자 나는 Fulltext Search를 검색했고, MySQL로는 한계가 있다는 사실을 인지하게 됐다.
그러다가 'Elastic search'라는 Full text index로 검색 엔진을 알게 됐다. 텍스트를 파싱해서 검색어 사전을 만들고, Inverted index 방식으로 text를 저장. 문장의 각 단어들을 통째로 저장하여 RDBMS보다 전문검색( Full Text Search)에 빠른 성능을 보여준다. 자세한 내용은 이 글을 참고하길 바란다.
결론: 검색은 Elastic Search를 적극 활용하자.
'성능 개선' 카테고리의 다른 글
| 대규모 트래픽 처리를 위한 클라우드 DB 활용 (삼성/쿠팡) (0) | 2023.05.11 |
|---|---|
| 서버 성능 올리기 (초급편) (1) | 2022.12.31 |

