Redis 적용 및 다양한 DataType
1. Redis 설치
소스와 바이너리 형태로 제공하며, 주로 리눅스에서 설치해 사용한다. 물론 Redis는 OS에 상관없이 어디든 사용 가능하다.
편의를 위해서 이 포스팅에서는 Docker에서 Redis를 간편히 설치하겠다.
도커 설치는 공식 홈페이지를 확인하면 된다.
docker pull redis
docker run --name my-redis -d -p 6379:6379 redis
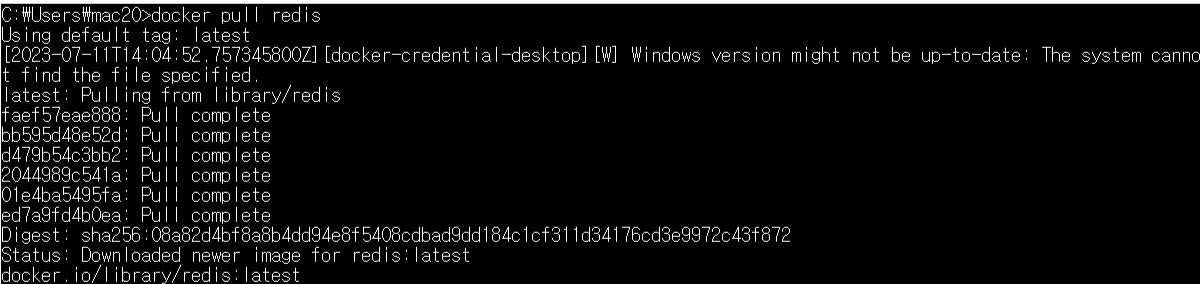

redis 이미지를 가져와서 my-redis라는 이름으로 6379 포트에 실행한다.

docker ps 명령어를 통해 redis 컨테이너가 실행됨을 확인할 수 있다.
2. Redis 실습
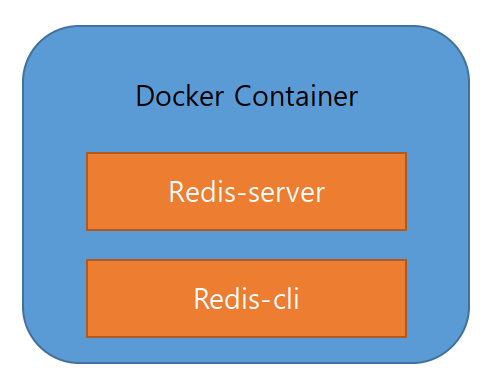
도커 컨테이너 안에서 실행되게끔 만들었다. Redis 모듈의 구조는 위의 사진과 같다. redis-server는 레디스 서버를 뜻하고, redis-cli는 레디스 서버에 커맨드를 실행할 수 있는 인터페이스이다.
도커 컨테이너 안에서 쉘을 실행하여 Container 내부의 redis-cli를 실행해 보겠다.

My-redis에 접속을 한다.

redis-cli를 실행한다.
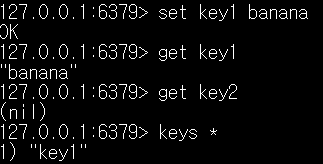
이렇게 Redis 명령어 수행이 가능하다. 참고로 별표를 이용한 모든 키값 조회는 성능에 영향을 끼치기에 실제로 수행하면 좋지 않는 명령어이다.
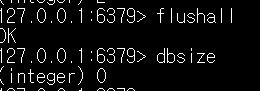
Flushall 명령어는 모든 키값들을 지운다.
exit 명령어로 처음 호스트로 돌아올 수 있다.
3. Redis Data Type
Redis는 다양한 데이터 타입을 제공한다.
3.1. Strings
가장 기본적인 타입으로 제일 많이 사용한다. 최대 크기는 512MB. 바이트 배열로 저장하며, 바이너리로 변환할 수 있는 모든 데이터를 저장 가능하다.(JPG와 같은 파일 등.)
※ 바이너리: 정보를 이진 형태로 저장한다. 모든 문자를 표현할 수 있다. 주로 캐시 같은 것들을 많이 표현.

INCR/DECR: Atomic하고, 손쉽게 count 구현이 가능하다.
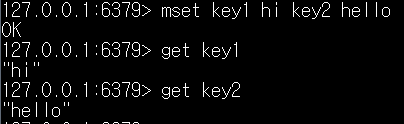
mset 명령어로 여러 개의 key value들을 삽입할 수 있다. 값을 확인해 보면 정상적으로 등록된 걸 확인할 수 있다.
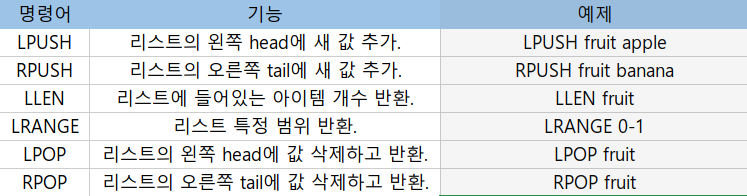
3.2. Lists

Linked-list 형태의 자료구조로 인덱스 접근은 느리지만, 데이터 추가/삭제가 빠르다. 데이터들이 포인터로 연결됐고, Queue와 Stack으로 사용할 수 있다.
3.3. Sets
순서가 없는 유니크한 값의 집합으로 검색이 빠르다. 인덱스가 존재하지 않고, 집합 연산(합집합, 교집합)이 가능하다.

대표적인 사용 예시로 웹 페이지에서 유효한 쿠폰 발급을 들 수 있다. 그 쿠폰을 발급받았는지 알아야 하는데, SET으로 그걸 확인할 수 있다.
3.4. Hashes
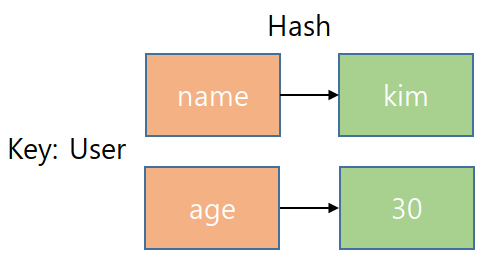
하나의 key 하위에 여러 개의 field-value 쌍을 저장하는 구조. 여러 필드를 가진 오브젝트를 저장하는 것으로 볼 수 있다.
특정 필드에만 접근하는 경우에 특정 필드를 지정해서 값을 가져올 수 있기에 조금 더 일부 필드에 대한 접근성이 좋다고 볼 수 있다. 하지만 여러 필드를 접근하는 경우 Hashes를 사용하면 불편하다. String을 사용하면 전체 필드를 JSON object로 저장하고, 불러올 수 있기 때문이다. 그래서 Hashes는 각각의 필드를 따로 사용할 때 활용성이 커진다.
대표적인 예시로 HINCRBY 명령어로 카운터로써 활용이 가능하다. 방문수, 클릭수, 유저에 관한 측정 숫자 등에 활용된다.

3.5. Sorted sets

Set과 유사하게 유니크한 값의 집합이다. 각 값은 연관된 score를 가지고 정렬됐다.
정렬된 상태기에 빠르게 최소/최대 값을 구하는 게 가능하다. 가장 앞은 최소, 가장 끝은 최대 이렇게 최소/최대 값을 빠르게 구할 수 있다.
보통 순위 계산이나 리더보드에 사용된다.

3.6. Bitmaps
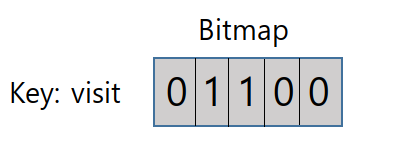
0과 1로 이루어진 긴 벡터로 공간 효율적으로 저장한다. 비트 벡터를 사용해 N개의 Set을 공간 효율적으로 저장한다. 하나의 비트맵이 가질 수 있는 공간은 2^32-1이다.
비트 연산이 가능하고, 오프셋을 사용한다. 이에 방문현황을 쓸 때 사용한다.

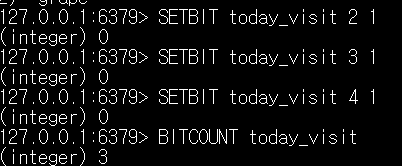
이렇게 특정값이 0이나 1을 세워야할 때 유용하다.
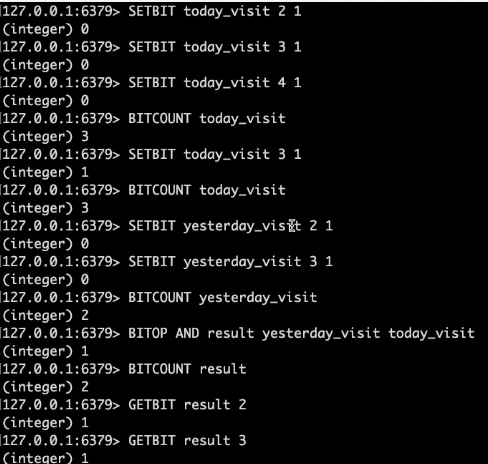
방문자 수를 구하거나, 어제와 오늘의 방문자 수 교집합을 비교할 때 사용하는 등. 활용성이 크다.
3.7. HyperLogLog

유니크한 값의 개수를 효율적으로 얻을 수 있다. 확률적 자료구조라서 오차가 있고, 매우 큰 데이터를 다룰 때 사용한다. 2^64개의 유니크 값을 계산 가능하다. 12KB까지 메모리를 사용하며 0.81%의 오차율을 허용한다.
Bitmaps 보다 여러가지 데이터들을 저장할 수 있어서 활용도가 높다. 대규모 데이터 처리할 때, 100%보다는 99% 이상의 조건이면 어떤 로직을 수행하는 경우가 많다.
HyperLogLog는 내부에 데이터를 저장하지 않는다.

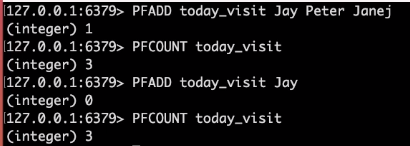
중복은 걸러지기 때문에 변화가 없다.
4. Spring Boot에 적용

'org.springframework.boot:spring-boot-starter-data-redis'
gradle에 해당 라이브러리를 넣는다.
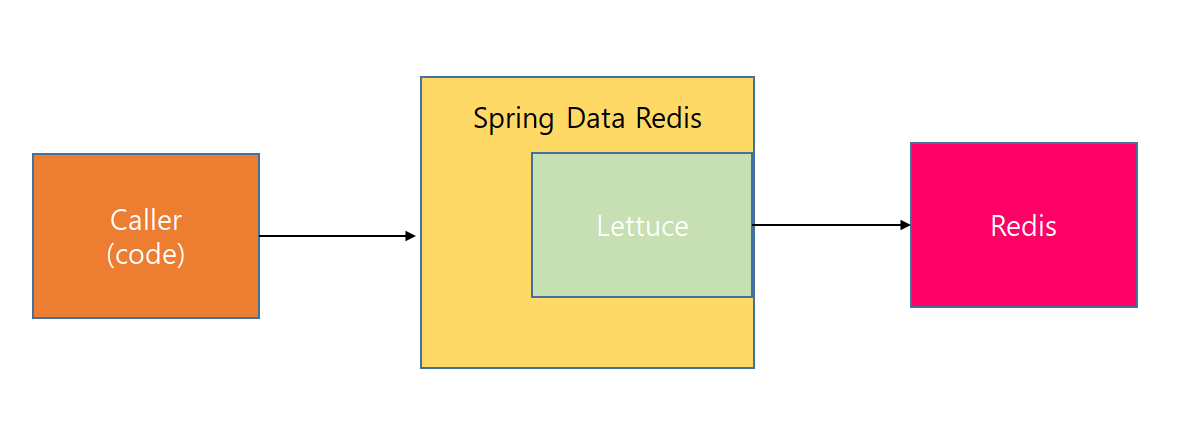
Lettuce는 스프링에서 제공하며 가장 많이 사용되는 라이브러리이다. Spring Data Redis에 내장됐다. Spring Data Redis는 Redis Template이라는 Redis 조작의 추상 레이어를 제공한다.
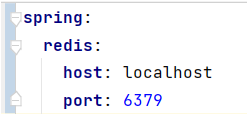
application.yml 파일에 해당 설정을 하면 redis가 적용된다. (포트는 6379)
위의 설정은 배포할 때 변경해줘야 한다.
출처: FastCampus 대용량 데이터 & 트래픽 처리