1. 최종 연산

Terminal Operation. 연산결과가 스트림이 아닌 연산, 단 한 번만 적용가능하다. 스트림의 요소를 소모한다.
- forEach(): 지정된 작업 수행.
- forEachOrdered(): 순서 유지. 병렬 스트림으로 처리할 때 작업 순서를 유지할 때 사용. forEach와 마찬가지로 지정된 작업을 수행한다.
- count(): 요소의 개수 반환.
- max(), min(): 최대값/최소값 반환.
- findAny(): 아무거나 하나 스트림의 요소를 반환.
- findFirst(): 첫번째 요소를 반환.
- allMatch(): 주어진 조건을 모두 만족하는지.
- anyMatch(): 주어진 조건들을 하나라도 만족하는지.
- noneMatch(): 모두 만족하는지 않는지.
- toArray(): 스트림의 모든 요소를 배열로 반환한다.
- reduce(): 스트림의 요소를 하나씩 줄여가면서 리듀싱 계산한다.
- collect(): 스트림의 요소를 수집한다.
2. 최종 연산 예시
1) 스트림의 모든 요소에 지정된 작업 수행 - forEach(), forEachOrdered()
void forEach(Consumer<? super T> action)
void forEachOrdered(Consumer<? super T> action)forEach는 병렬스트림인 경우 순서가 보장되지 않는다. forEachOrdered는 병렬스트림인 경우 순서가 보장된다.
IntStream.range(1,10).parallel().forEach(System.out::print); //681924537
IntStream.range(1,10).parallel().forEachOrdered(System.out::print); //123456789병렬은 스레드 때문에 여러 스레드가 나눠 처리하기에 순서가 달라진다.
parallel()로 병렬로 만들었음에도 forEachOrdered는 순서가 보장된 걸 알 수 있다.
2) 조건 검사 - allMatch(), anyMatch(), noneMatch()
boolean allMatch(Predicate<? super T> predicate)
boolean anyMatch(Predicate<? super T> predicate)
boolean noneMatch(Predicate<? super T> predicate)
allMatch는 모든 요소가 조건 만족 시에 true, anyMatch는 한 요소라도 조건 만족 시에 true, noneMatch는 모든 요소가 조건을 만족시키지 않으면 true를 반환한다.
boolean hasFailed = clasStream.anyMatch(c->c.getTotalScore()<=100);
전체 점수가 100점을 넘어가지 않으면 failed 시켰다.
3) 조건에 일치하는 요소 찾기 - findFirst(), findAny()
Optional<T> findFirst()
Optional<T> findAny()findFirst는 첫 번째 요소를 반환하며 주로 직렬 스트림에서 사용한다. 반면 findAny는 아무거나 하나를 반환하며 병렬 스트림에 사용한다.
Optional<Student> result = stuStream.filter(s->s.getTotalScore() <=100).findFirst();findFirst를 이용해 총점이 100 이하인 학생 중에 첫 번째 학생을 뽑았다.
4) 스트림 요소를 하나씩 줄여 누적연산 수행 - reduce() (★★★)
Optional<T> reduce(BinaryOperator<T> accumulator)
T reduce(T identity, BinaryOperator<T> accumulator)여기서 identity는 초기값을 의미하고, accumulator는 이전 연산결과와 스트림의 요소에 수행할 연산을 뜻한다.
int count = intStream.reduce(0, (a,b) -> a+1);
int max = intStream.reduce(Integer.MIN_VALUE, (a,b)-> a>b a: b);count는 0에서 이전 요소를 계속 더해서 사실상 count()랑 비슷하다. max는 최솟값에서 이전 요소의 최대 요소를 찾아서 사실상 max() 함수랑 같다.
실무에서 자주 사용되기에 최종 연산 중에서 reduce가 제일 중요하다.
3. Collect
1) 정의
Collector를 매개변수로 하는 스트림의 최종연산 - collect()
Object collect(Collector collector)Collector를 구현할 클래스의 객체가 매개변수이다. collect는 그룹별로 리듀싱한다.
여기서 Collector는 수집(collect)에 필요한 메서드를 정의한 인터페이스이다.
Collectors는 클래스이며 다양한 기능의 컬렉트를 제공한다.
mapping(), toList(), toSet(), toMap() ... //변환
counting(), summingInt(), averagingInt(), maxBy(), minBy(), summarizingInt()... // 통계
joining() // 문자열 결합
reducing() // 리듀싱
groupingBy(), partitionBy(), collectingAndThen() // 그룹화와 분할위의 기능들을 직접 구현할 이유가 없다. Collectors 클래스만 잘 사용할 줄 알면 된다.
2) 스트림을 컬렉션 or 배열로 변환 - toList(), toSet(), toMap(), toCollection()
List<String> name = studentStream.map(Student::getName)
.collect(Collectors.toList())Collectors의 toList를 활용하여 List 배열로 만들었다.
ArrayList<String> list = names.stream()
.collect(Collectors.toCollection(ArrayList::new));toCollection의 ArrayList를 넣어주니 Stream이 ArrayList로 변화했다.
Map<String, Person> map = personStream
.collect(Collectors.toMap(p->p.getRegId(), p ->p));toMap을 활용해 Stream을 Map<String,Person>으로 변경하였다. map은 key와 value가 필요하기에 p.getId를 key로 넣고 person을 값으로 넣었다.
3) 스트림을 배열로 변환 - toArray()
Student[] studentNames = studentStream.toArray(Student[]::new);
Student[] studentNames = studentStream.toArray(); // 자동 형변환이 안 됨.
Object[] studentNames = studentStream.toArray();Student[] studentNames = (Student[]) studentStream.toArray(); 이런 식으로 형변환을 해줘야 한다.
그래서 Object[] studentNames = studentStream.toArray(); 이런 식으로 Object를 많이 사용된다.
4) 스트림의 통계 - counting(), summingInt()
스트림의 통계정보를 제공해준다. counting 외에도 maxBy(), minBy()를 많이 사용한다.
long count = studentStream.count();
long count = studentStream.collect(Collectors.counting());
studentStream.count()는 전체의 개수를 센다. 반면 studentStream.collect(Collectors.counting())는 그룹별로 나눠서 카운팅 가능하다는 걸 알 수 있다.
5) 스트림을 리듀싱 - reducing()
Collectors reducing(BinaryOperator<T> op)
Collectors reducing(T identity, BinaryOperation<T> op)
Collectors reducing(U identity, Function<T,U> mapper, BinaryOperator<U> op)그룹별로 리듀싱한다. 그룹별 count(), 그룹별 sum() 등이 가능해진다.
Optional<Integer> max = intStream.box().collect(reducing(Integer::max));위의 코드는 그룹별로 max 최댓값을 구했다.
6) 문자열 스트림의 요소를 연결 - joining()
String student = studentStream.map.(Student::getName).collect(joining(","));
String student = studentStream.collect(joining(","));문자마다 ','로 연결한다. studentStream.collect(joining(","))은 Student의 toString()으로 결합할 수 있다.
7) 스트림을 2분할 - partitioningBy()
partitioningBy가 groupingBy보다 더 빠르다.
Map<Boolean, List<Student>> studentBySex = studentStream
.collect(partitioningBy(Student::isMale));
List<Student> maleStudent = studentBySex.get(true);
List<Student> femaleStudent = studentBySex.get(false);학생들을 성별로 분리한다. 데이터 형태는 아래와 같다.
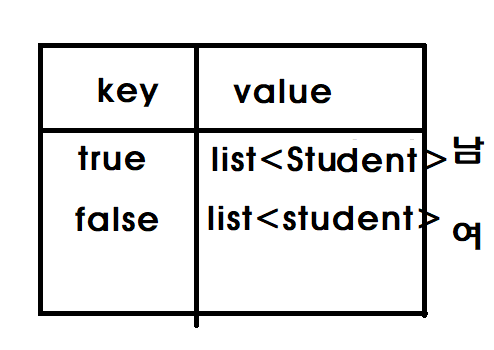
get(true)면 남자이고 get(false)면 여성이다.
Map<Boolean, List<Student>> studentBySex = studentStream
.collect(partitioningBy(Student::isMale, counting()));위 코드는 분할+통계를 한 것이다. 남학생 수: 5명, 여학생 수: 10명 이런 식으로 분할하고 숫자를 셀 수 있다.
8) 스트림을 n분할 - groupingBy()
Map<Integer, List<Student>> studentByClass = studentStream
.collect(groupingBy(Student::getClass, toList()));partionBy와 비슷하다. 단지 2개가 n개로 늘렸을 뿐이다.
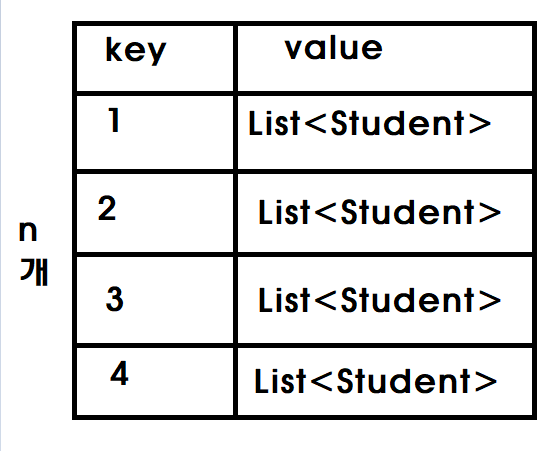
1반의 List<Student> 2반의 List<Student> 이런 식으로 map이 정의됐다.
Map<Integer, Map<Integer,List<Student>> studentByClass = studentStream
.collect(groupingBy(Student::getClass,
groupingBy(Student:getClass));위의 코드는 복잡해 보이지만, 위의 코드와 비슷하다. 1) 학년별 그룹화를 하고, 2) 반별 그룹화를 했다.
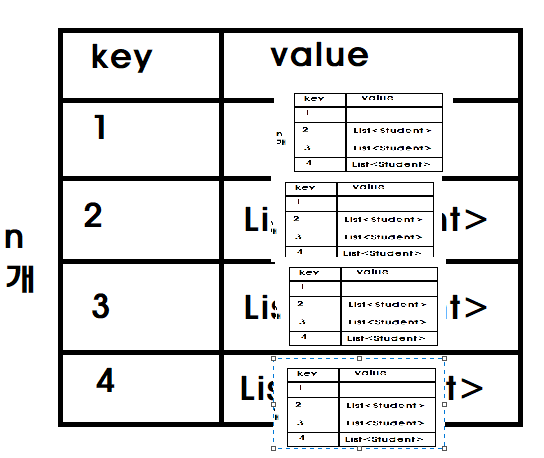
맵 안의 맵이 들어간 형태이다.
출처: 자바의 정석
'JAVA > JAVA' 카테고리의 다른 글
| Optional 개념과 활용 (0) | 2023.01.07 |
|---|---|
| 스트림(Stream) - 중간 연산(2/3) (0) | 2023.01.04 |
| 스트림(Stream) - 개념(1/3) (0) | 2023.01.03 |
| Generics 지네릭스 - 와일드 카드 및 메소드 (2/2) (0) | 2023.01.02 |
| Generics 지네릭스 - 개념 및 활용 (1/2) (0) | 2023.01.02 |


