1. S3를 왜 사용할까?
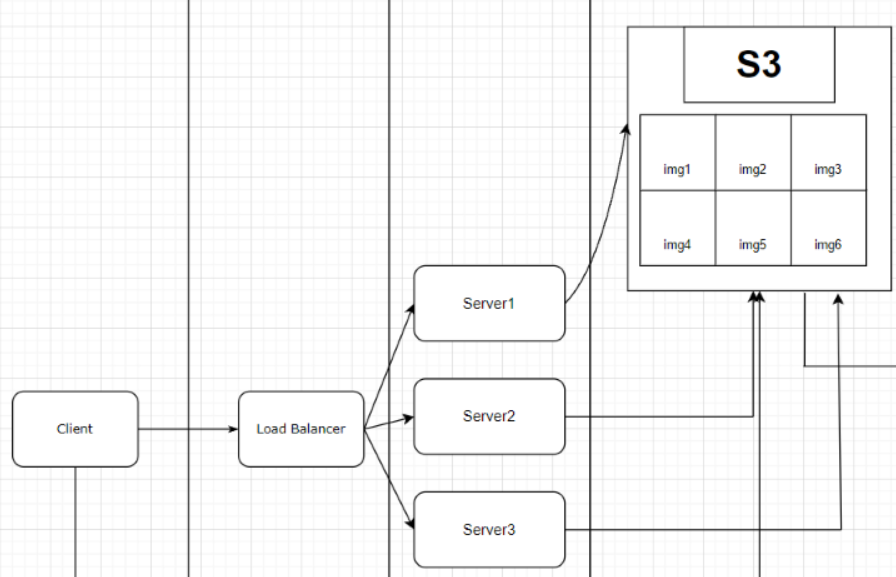
나중에 서비스가 커질 때, 서버를 확장해야 할 때가 있습니다. 이럴 때는 아래의 방식처럼 서버를 확장해야 합니다.

Load Balancer는 요청이 들어오면 서버의 부하가 없는 곳에 전해줍니다. 이럴 경우 아래의 사건들이 발생합니다.
- DB: 서버와 완전 무관합니다. 처리하고 호출만 해줘서, 중앙화된 서버가 있어서 똑같은 데이터를 바라보기에 상관이 없습니다.
- 이미지: 아미지 파일들이 흩어져서 저장됩니다. 즉, 서버들이 상태를 갖게 됩니다. Stateful 한 상태가 되면 아래의 세 가지 문제가 발생합니다.
- 이미지 관리: 예를 들어 img6이 loadBalancer를 통해 Server3에서 저장이 됐는데 Server1에서 삭제하려고 하면 삭제를 못 합니다.
- 서버 축소: 항상 서버가 3대만 있는 게 아닙니다. 부하가 줄어들면 자동으로 서버 수를 줄이게 되는데, 이러면 그 서버에 저장된 이미지도 같이 삭제됩니다.
- 성능적인 측면: 이미지를 관리하는 걸 서버를 통해서 하면, 메인 서버가 다른 작업을 하는데 퍼포먼스 상으로 영향을 줘서 성능에 영향을 줄 수 있다.
2. S3 사용
S3를 사용하면 위의 Stateful한 문제를 손쉽게 해결할 수 있습니다.

Amazon Simple Storage Service(Amazon S3)는 확장성, 데이터 가용성, 보안 및 성능을 제공하는 객체 스토리지 서비스입니다. S3를 이용하여 웹 사이트, 모바일 애플리케이션, 백업 및 복원, 빅 데이터 분석 등 다양한 곳에서 사용됩니다. S3에서 원하는 양의 데이터를 저장하고 보호할 수 있습니다.
S3의 이점은 다음과 같습니다.
- S3 저장소를 별도로 둬서 Stateless한 상태가 됩니다.
- 이미지뿐만 아니라 영상, 파일도 더 이상 서버에 저장하지 않고, S3에 저장할 수 있습니다.
- Stateless 한 상태가 돼서 서버의 확장성이 좋아집니다.
S3는 Stateless 상태뿐만 아니라 서버의 성능도 올려줍니다.

정적 파일 트래픽 분리(CDN)로 클라이언트와 서버 사이의 대기 시간을 줄여줍니다. S3의 CDN 적용은 3편에서 설명하겠습니다. 참고로 성능이 올라가는 이유는 이곳에서 자세히 설명됐습니다.
3. S3 Bucket
1) S3 생성
S3를 쓰는 이유를 설명했으니 이제 본격적으로 S3를 생성해 보겠습니다.
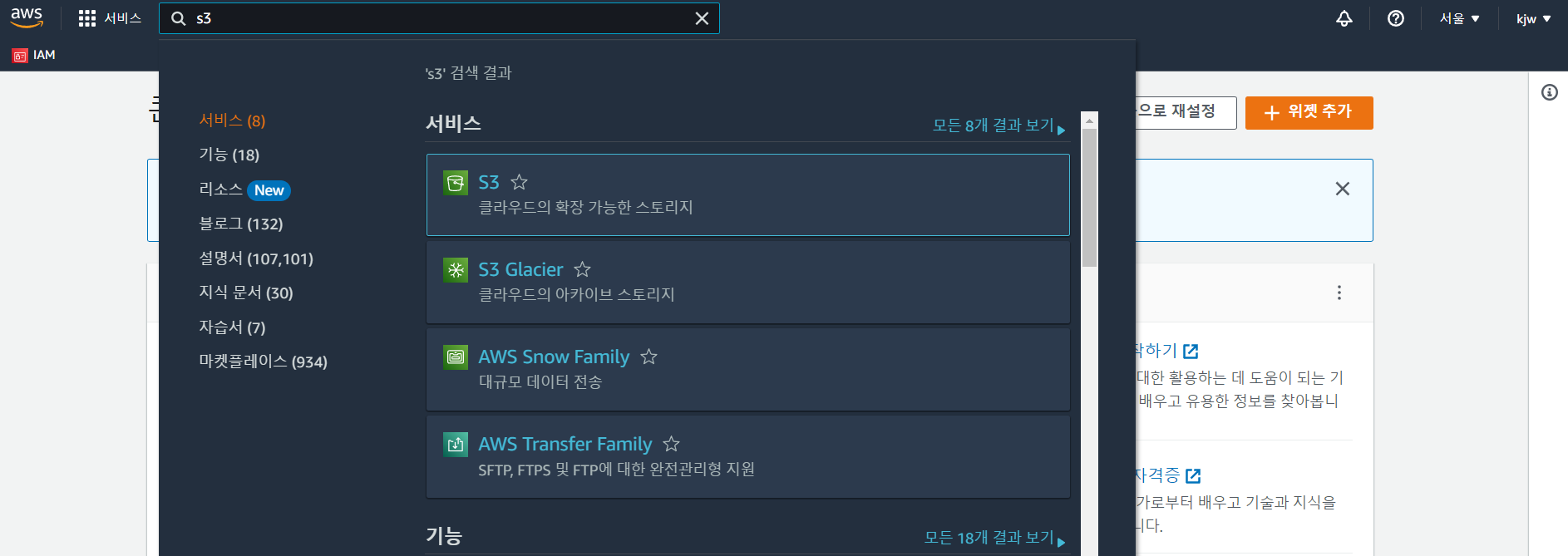
s3를 검색하고
버킷 만들기로 버킷을 생성해 줍니다.
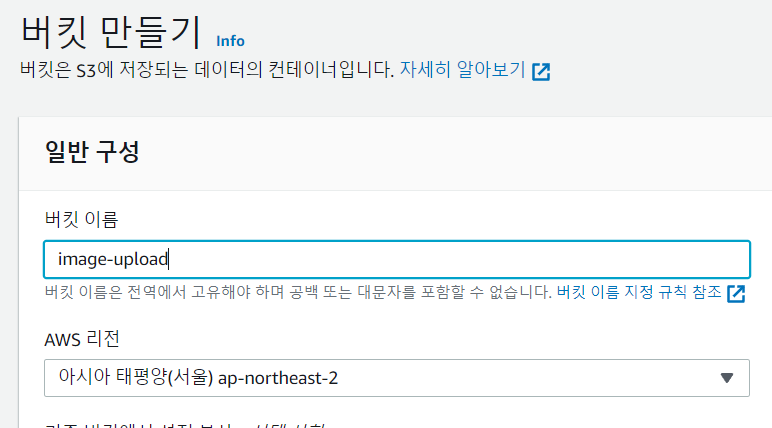
버킷 이름을 지어주고 AWS 리전을 서울로 선택합니다.
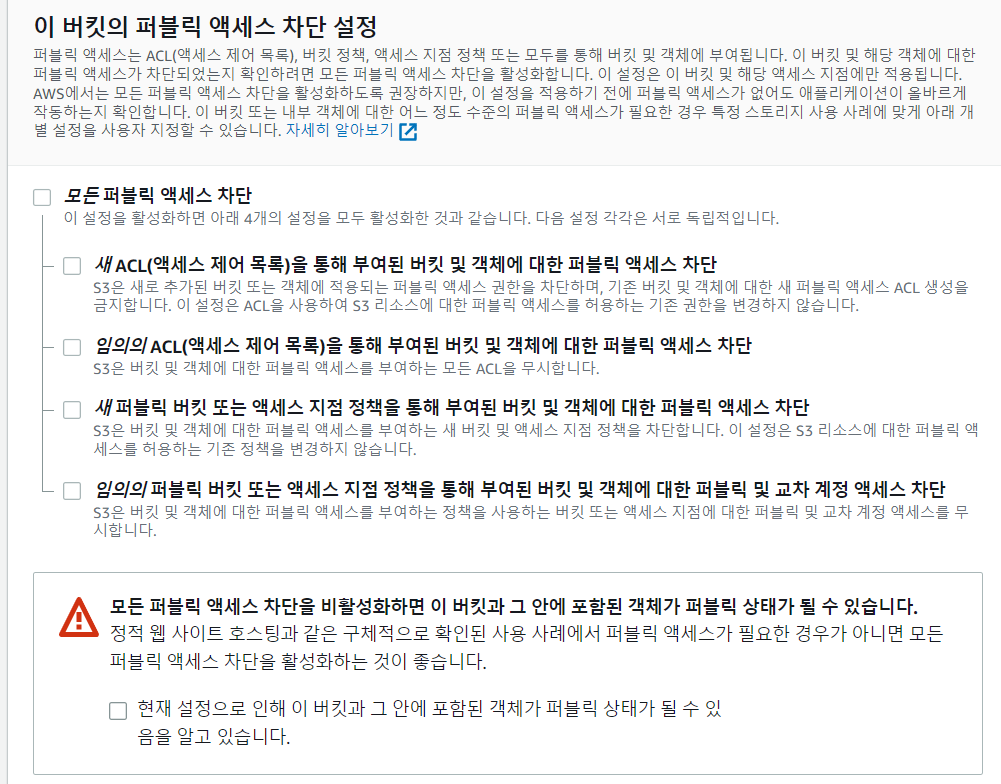
사진 파일들은 외부에 공개되는 public 한 사진들이기에 해제해줘야 합니다. 근데 만약 절대 공개되지 말아야 할 서류들이나 중요 문서들이라면 차단하고 불러오면 됩니다.

위를 클릭하고 버킷 만들기를 해주면 됩니다.
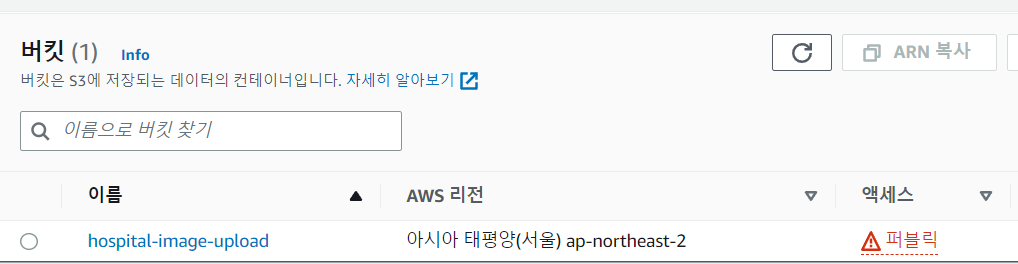
이렇게 버킷이 만들어진 걸 확인할 수 있습니다.
2) 버킷 정책 설정(★)
이미지를 조회하는 것은 S3를 거치지 않고 바로 조회할 수 있게끔 설정했습니다.(모든 퍼블릭 액세스 차단 해제)
버킷의 정책을 설정해줘야 하는 건 외부에서 이미지를 삭제하는 걸 방지하기 위해 설정을 잘해줘야 합니다.
이미지를 생성하거나 삭제는 서버를 걸쳐서 검증 후에 실행이 되어야 합니다. 이를 위해 accessKey와 secretKey를 발급받아야 합니다. 액세스 키와 시크릿 키가 있어야 백엔드가 인증을 해서 생성과 삭제가 가능해집니다.
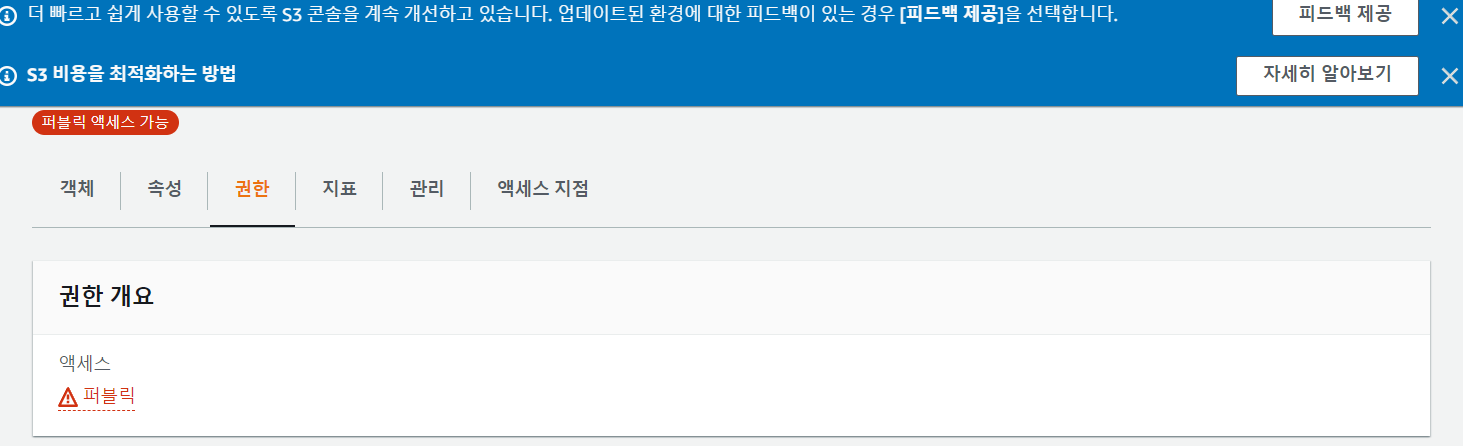
권한에 들어가 줍니다.

편집에 들어가서 정책 생성기로 정책을 생성해 줍니다.

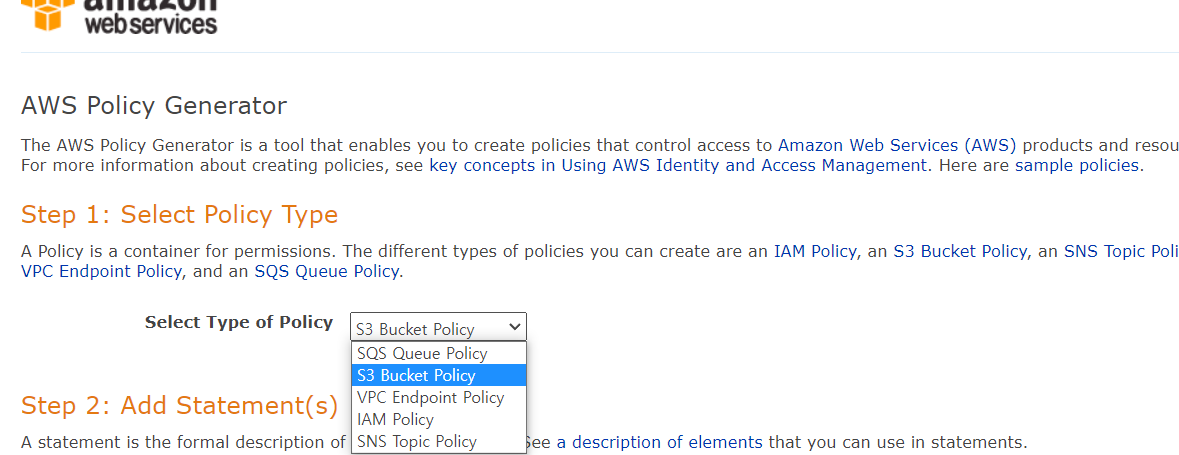
S3 Bucket Policy 선택.
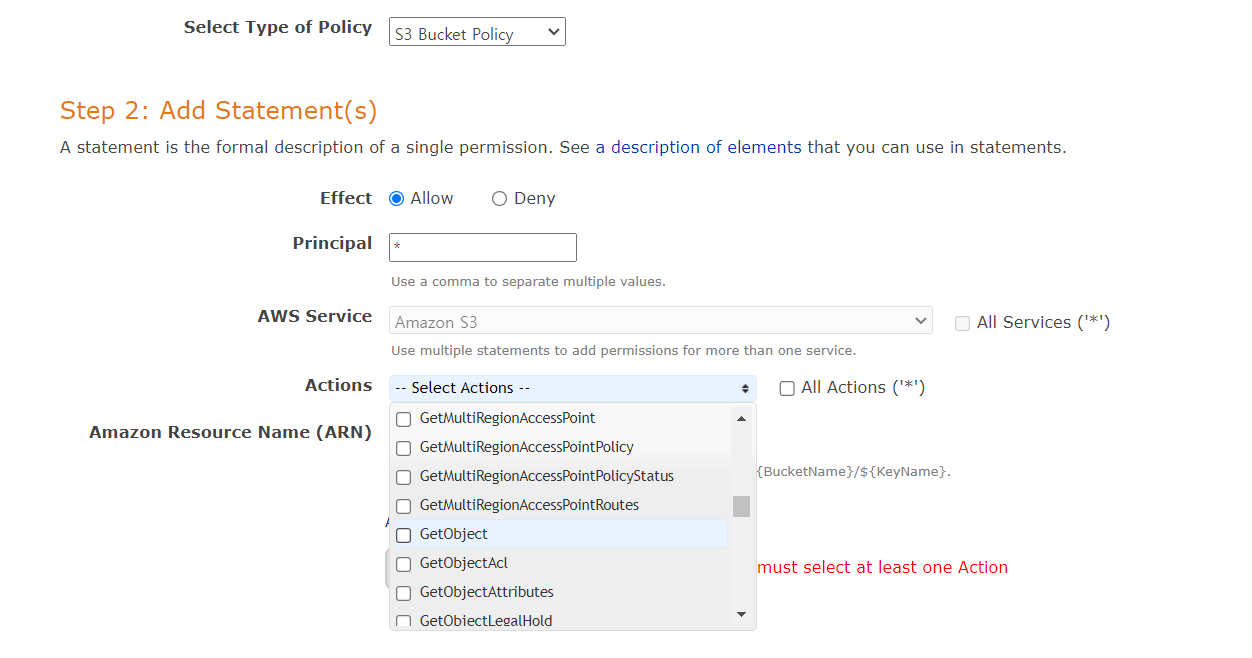
GetObject 선택.
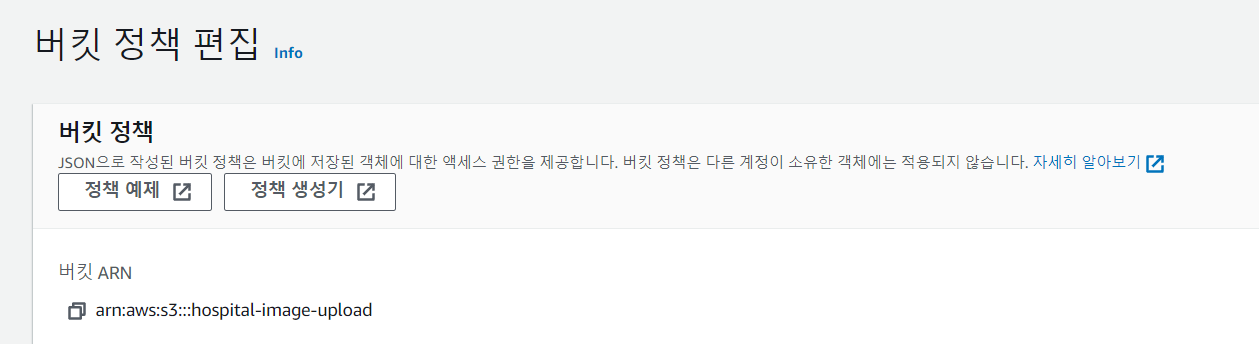
버킷 ARN 복사.
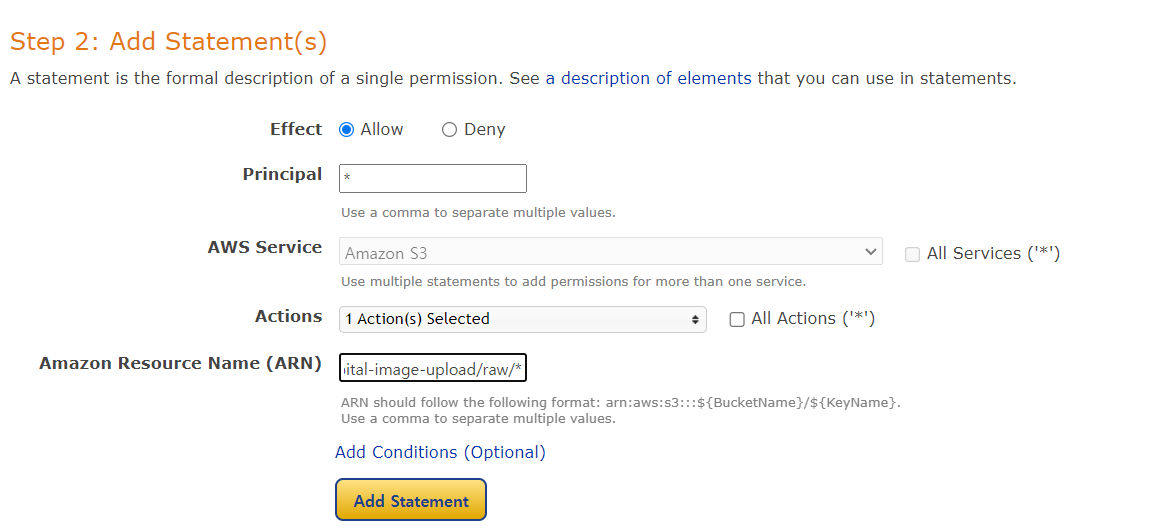
ARN을 붙여놓고 뒤에 /raw라는 폴더를 만듭니다. /raw/*는 raw라는 폴더를 만들고 *은 모든 파일을 노출하겠다는 뜻입니다.
Add Statement를 하고 Generate Policy를 하면 아래와 같이 나온다.
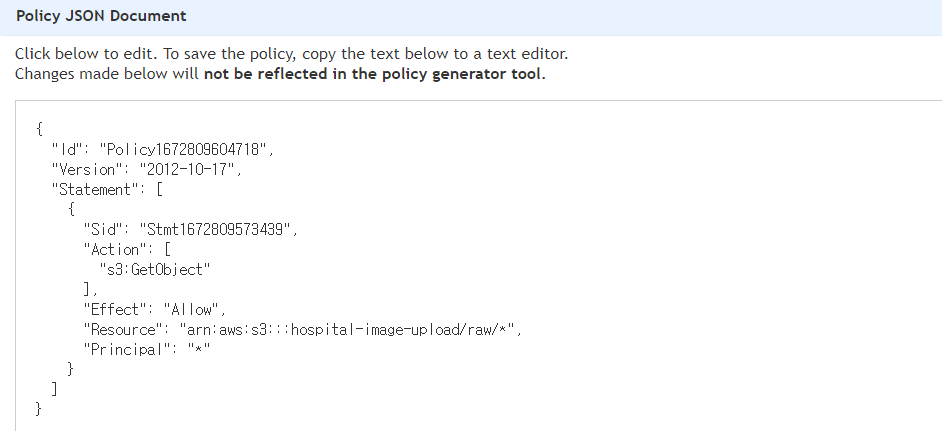
이걸 복사해서 Bucket 정책에 붙여 넣기 하면 됩니다.
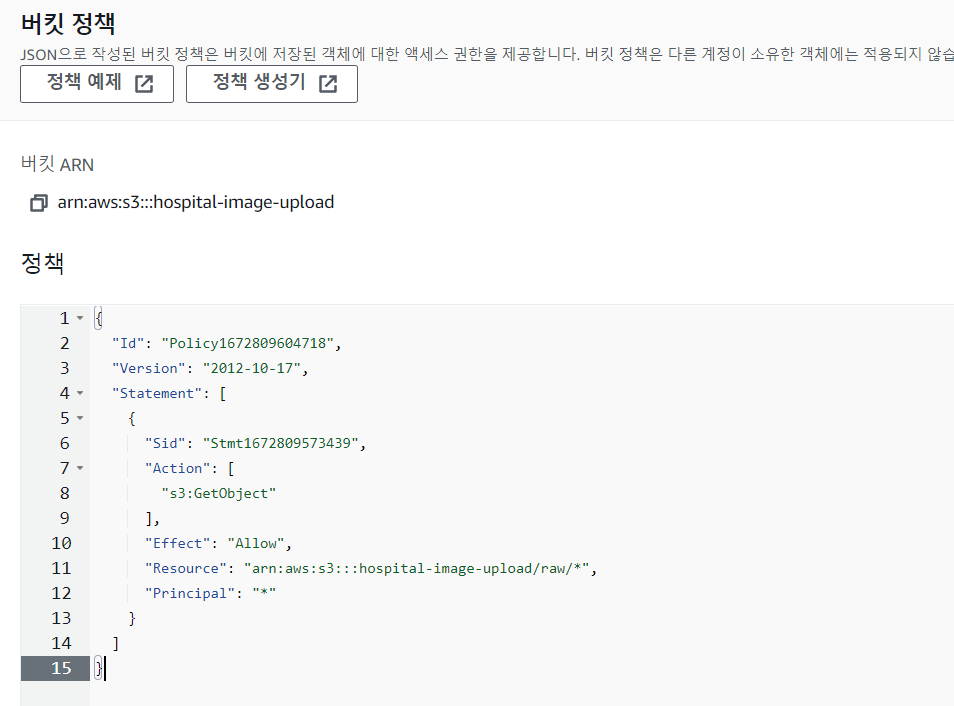
그리고 밑에 변경 사항 저장을 누르면 끝.
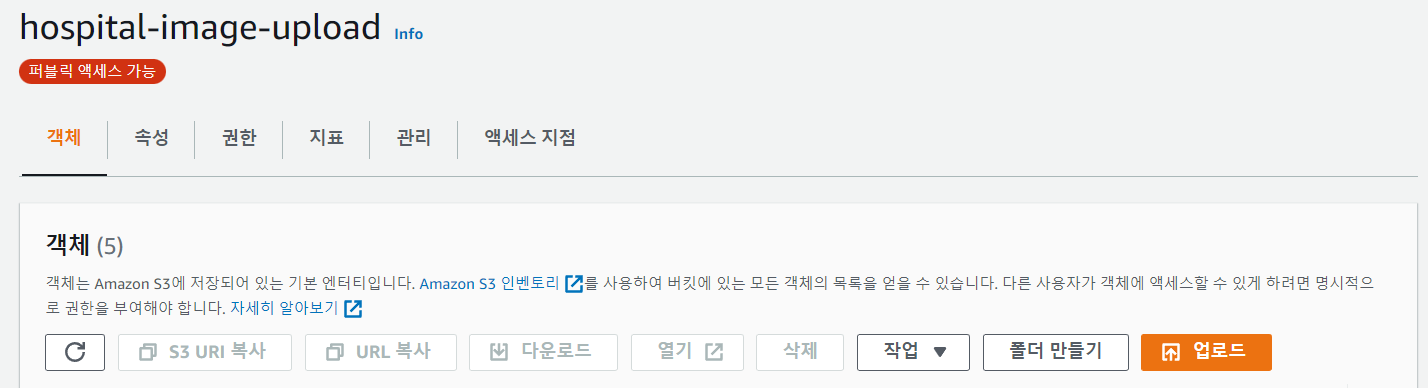
폴더 만들기를 통해 raw를 만듭니다.
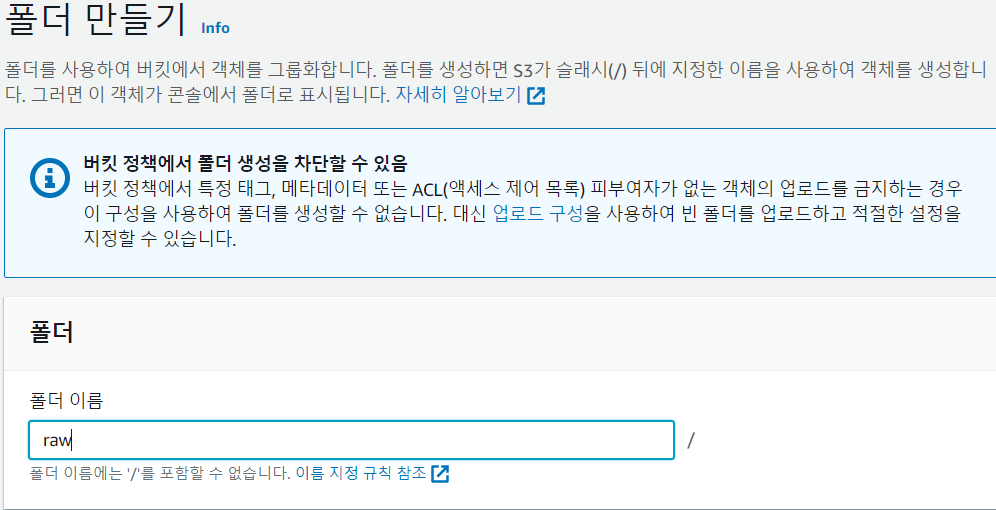
이전에 정책을 만들었던 것은 raw 폴더 안에 있는 파일들만 외부에서 접근이 가능하도록 설정했습니다. raw 폴더 밖의 파일들은 외부에서 접근이 불가능합니다.
3) 백엔드를 위한 정책 만들기
이미지 저장과 삭제는 백엔드를 걸쳐서 해야 합니다. 이를 위해 AWS에서 새로운 정책을 만들어야 합니다. 사용자(백엔드)는 자신만의 고유한 access key와 secret key를 발급받고. 그 key를 가진 사람은 해당 정책을 소유하게 되고 실행할 수 있게 됩니다.
위의 내용들을 정리하면
정책 생성 => 정책을 갖게 되는 사용자 => 사용자의 id와 pw를 백엔드에서 저장 =>
백엔드는 그걸 가지고 로그인을 해서 정책을 활용(이미지 저장, 삭제)
IAM에 들어갑니다. IAM은 인증 인가를 통합적으로 관리합니다.
개발이 커지면 개발자들이 많아질 텐데 모든 개발자들이 AWS 모든 권한을 가지고 있으면, 미숙련자의 실수로 S3의 버킷을 통째로 삭제한다든지 그런 대형 사고를 방지하기 위해 권한을 축소합니다.
그런 실수를 방지하기 위해서 권한을 최소화. 각 서비스별로 하는 역할이 다를 겁니다. 어떤 사람은 A라는 버킷에 권한을 주고, 어떤 사람은 B에 관한 버킷만 관리하니까 B에 관한 버킷에 권한만 주고 이런 식으로 권한을 제약하는 게 좋습니다.
그리고 클라이언트가 백엔드를 호출할 때 최대한 input 변수를 최소화하는 게 좋습니다. 그래야 실수의 여지가 줄어들고 백엔드에서도 경우의 수가 줄기 때문에 버그가 날 확률이 줄어듭니다. 그래서 권한과 input을 최소화하는 게 좋습니다.
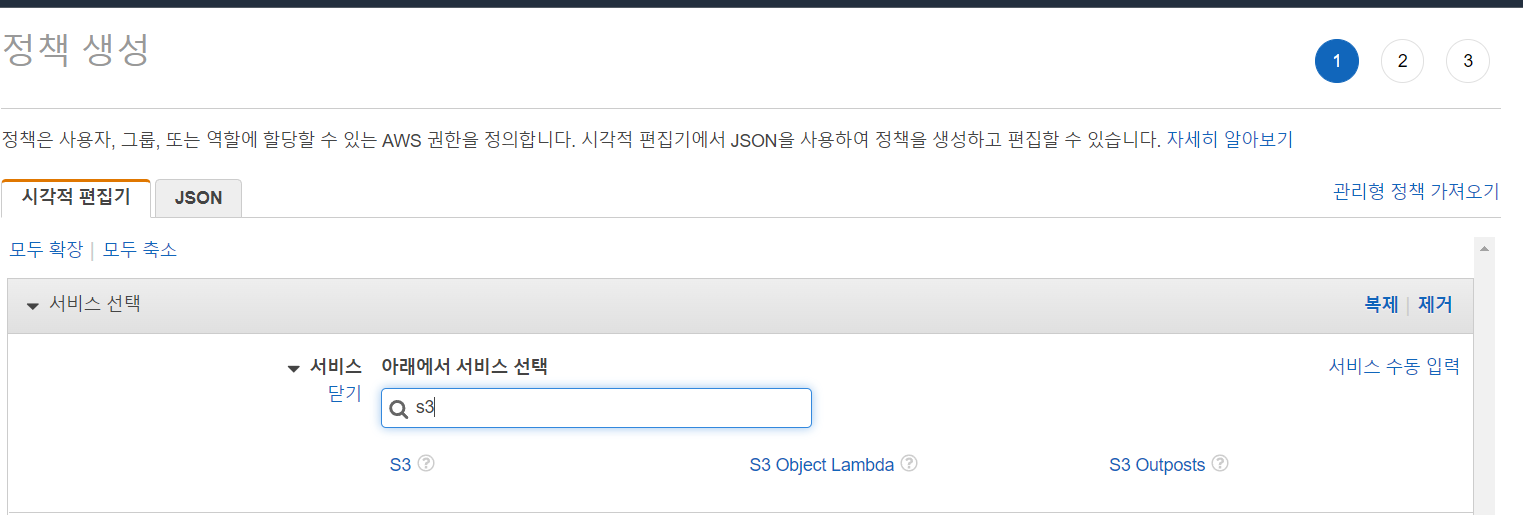
정책에 들어갑니다. 정책 생성.
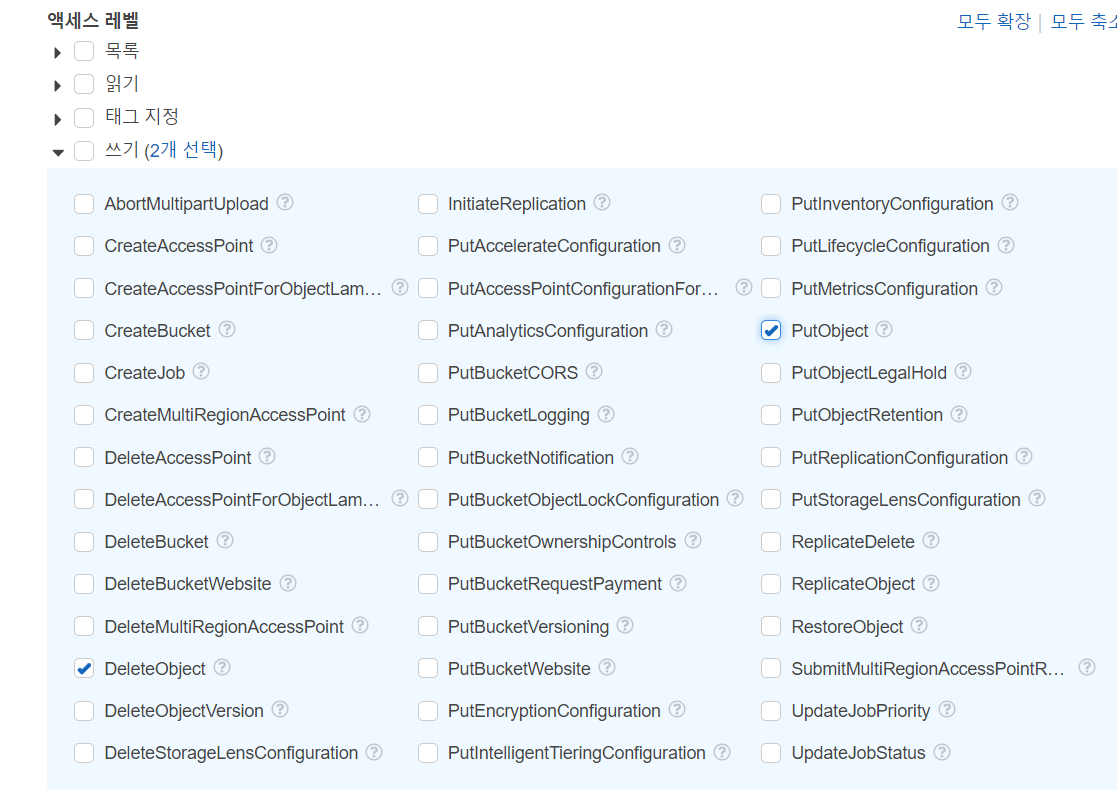
이미지를 생성과 삭제만 있으면 되기에 putObject와 DeleteObject를 설정합니다.
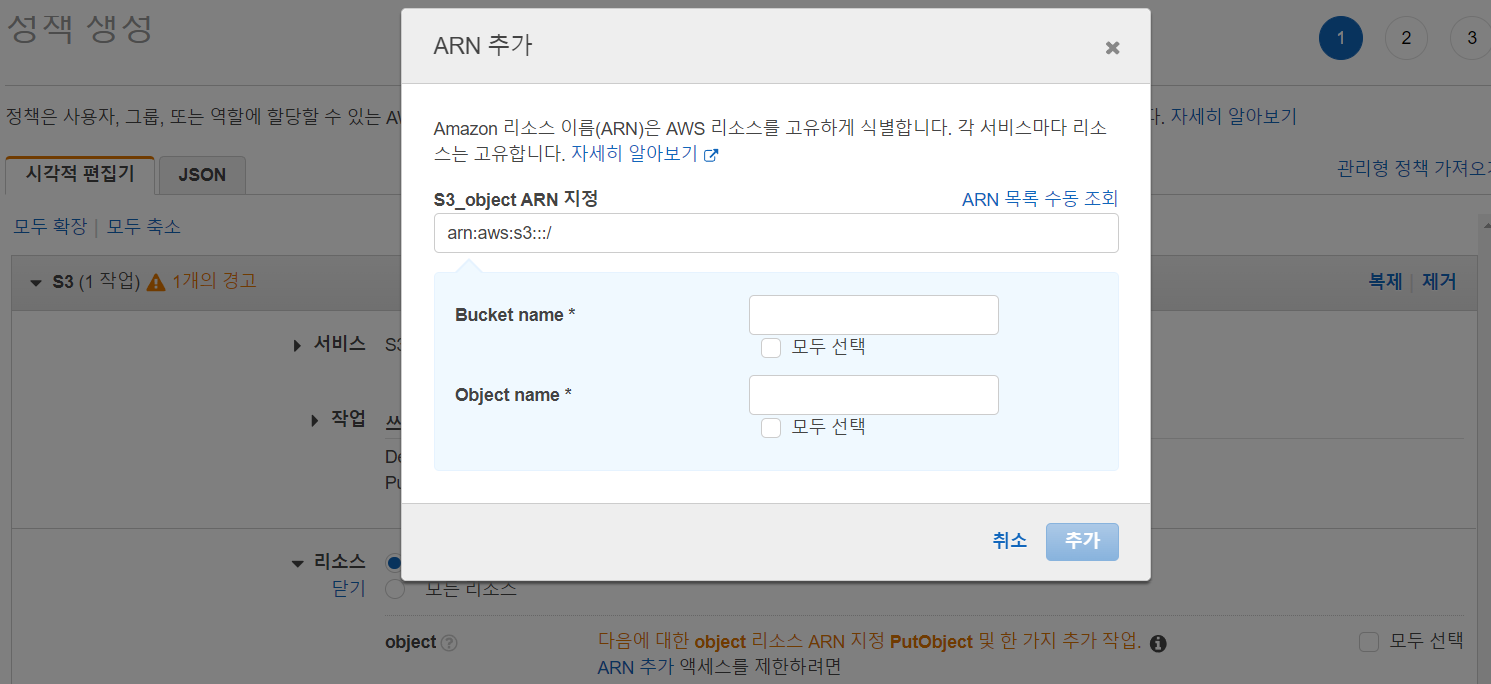
이전에 만들었던 S3 버킷의 정책을 확인해서

Resource 부분. "arn:aws:s3:::hospital-image-upload/raw/*"을 복사합니다. (각자 파일 이름이 달라서 맞춰서 하시면 됩니다.)
앞으로 이미지 리사이징을 할 건데 raw 폴더를 한정하는 건 제약이 있기에 전체로 설정했습니다.
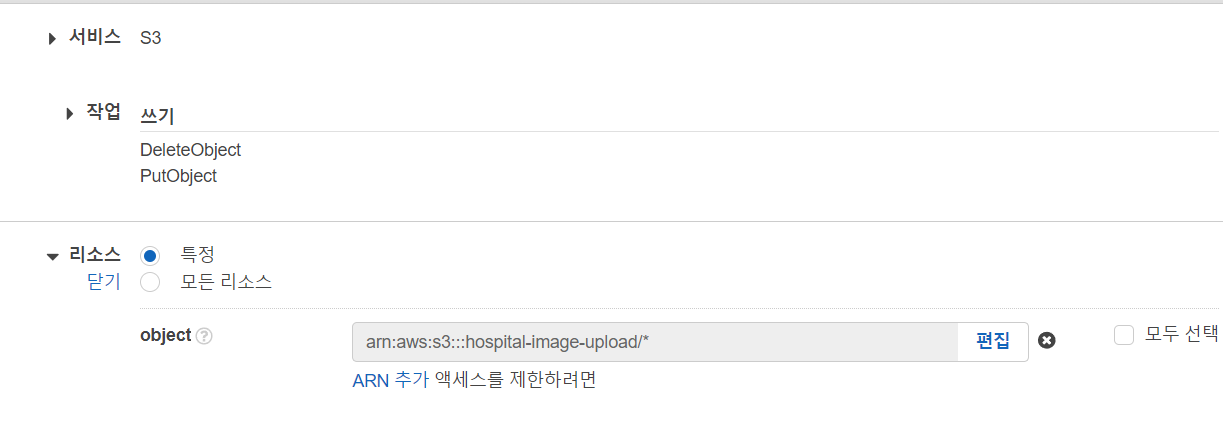
resource를 추가하면 다음과 같이 나옵니다. 계속 다음을 누르면
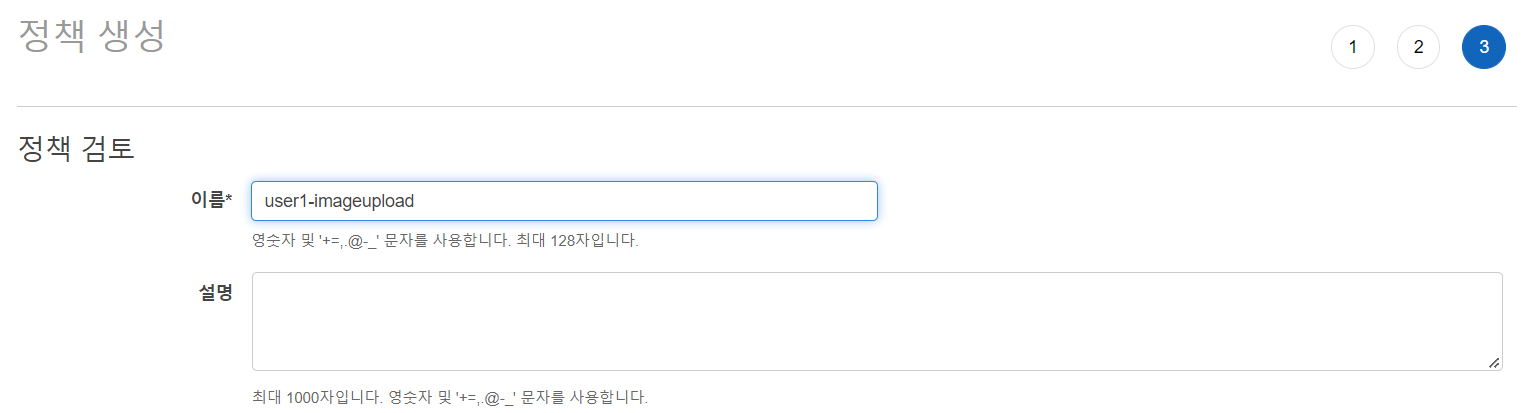
정책 이름을 지정해 주고 정책 생성을 해주면 됩니다.
이제 사용자를 만들겠습니다. 사용자 탭에 들어가 사용자를 만들어줍니다.
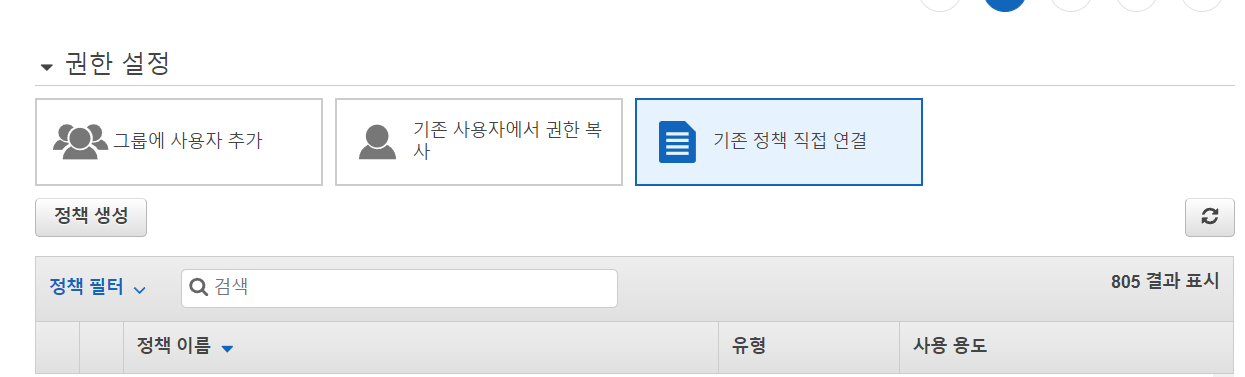
내가 만든 정책을 검색해 줍니다.
계속 다음을 누르고 사용자 만들기 버튼을 누릅니다.
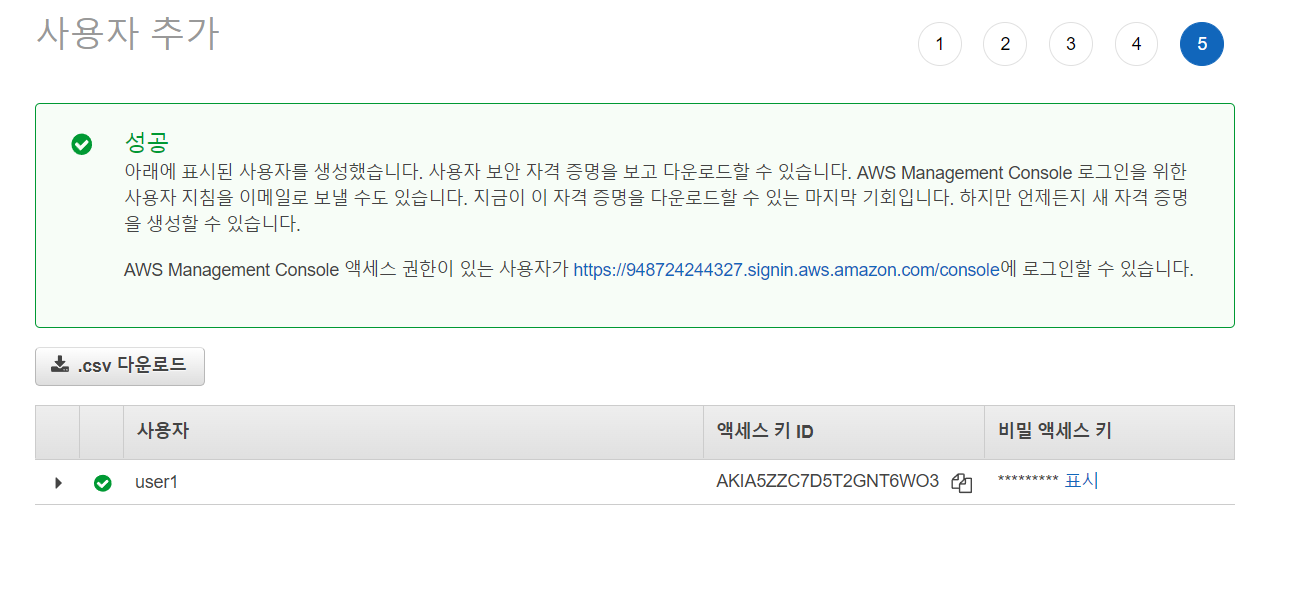
비밀 액세스 키는 이번 기회에만 확인할 수 있습니다. 그렇기에 꼭 어딘가에 저장해둬야 합니다. 비밀 엑세스 키는 절대 외부로 노출하면 안 됩니다.
4. S3와 Spring Boot 연동.
application.yml 파일에
spring:
profiles:
include:
- db
- jwt
- aws이런 식으로 설정했습니다. profiles에 설정한 이유는 깃허브에 올릴 때 aws의 secretKey는 절대 외부에 노출하면 안 되기에 aws.yml 파일을 git Ignore 하기 위해서입니다.
저는 aws 설정 부분을 application-aws.yml 파일명으로 설정했습니다. 꼭 파일 형식을 'application-파일명' 형식으로 맞춰줘야 인식이 됩니다.
application-aws.yml 파일은 다음과 같이 설정해 줬습니다.
cloud:
aws:
credentials:
accessKey: 엑세스키
secretKey: 시크릿키
s3:
bucket: 버킷명
region:
static: ap-northeast-2
stack:
auto: false이전에 발급받았던 액세스키와 시크릿키를 복붙 해주시고, 자신의 버킷명에 따라 버킷을 설정해 주시면 됩니다.
그리고 configuration 패키지를 생성하시고 그 안에 자바 파일을 아래와 같이 설정해주시면 됩니다.
@Configuration
public class AmazonS3Config {
@Value("${cloud.aws.credentials.access-key}")
private String accessKey;
@Value("${cloud.aws.credentials.secret-key}")
private String secretKey;
@Value("${cloud.aws.region.static}")
private String region;
@Bean
public AmazonS3Client amazonS3Client() {
BasicAWSCredentials awsCreds = new BasicAWSCredentials(accessKey, secretKey);
return (AmazonS3Client) AmazonS3ClientBuilder.standard()
.withRegion(region)
.withCredentials(new AWSStaticCredentialsProvider(awsCreds))
.build();
}
}여기서 @value는 application-aws.yml에서 입력한 값들을 인식합니다. yml 파일에 입력한 access-key, secret-key, region을 불러옵니다.
이렇게 amazonS3client를 빈으로 등록하여 기본적인 S3 세팅은 끝냈습니다. 다음 2편부터는 S3 버킷과 Vue.js, Spring Boot를 서로 어떻게 연동시키는지 알아보겠습니다.
'DevOps > AWS' 카테고리의 다른 글
| EC2로 24시간 서버 운영 - Nginx (3/3) (0) | 2023.02.06 |
|---|---|
| EC2로 24시간 서버 운영 - RDS (2/3) (0) | 2023.02.03 |
| EC2로 24시간 서버 운영 - Spring boot + vue.js (1/3) (0) | 2023.02.01 |
| AWS S3 + Vue.js + SpringBoot(3/3) - CDN, Lambda 적용하기 (0) | 2023.01.06 |
| AWS S3 + Vue.js + SpringBoot(2/3) - S3와 프론트, 서버 연동 (0) | 2023.01.05 |



