1. 확장성과 분산
확장성은 서비스가 커질 때 대응할 수 있는 능력을 뜻한다. 주로 규모에 대한 확장성을 의미한다. 방식은 수직 확장(Scale-up)과 수평 확장(Scale-out)이 있다.
1.1 수직 확장(Scale-up)

단일 하드웨어의 리소스(CPU, 메모리, 네트워크 어댑터 등)를 추가하거나, 기존 하드웨어를 고성능으로 교체하는 것을 의미한다.
1.2 수평 확장(Scale-out)
서버를 여러 개를 둬서 작업을 분산한다. 이론적으로 무한대로 확장이 가능하다. 그러나 수직 확장에 비해 매우 까다롭다.
수평 확장을 하면 아래와 같은 개발 복잡성이 많아진다.
- 부분 장애
- 네트워크 실패
- 데이터 동기화
- 로드밸런싱
- 개발 및 관리의 복잡성
그럼에도 서비스 복잡도와 규모의 증가로 분산은 피할 수 없기에 많이 사용하는 편이다. 분산 구현체들은 세부적인 부분에서 튜닝이 가능하게 옵션이 제공되는 편이다. (분산 시스템의 장단점을 세부적으로 조절할 수 있다.)
2. Cluster
클러스트는 Redis 뿐만 아니라 DB에서도 비슷한 원리와 원칙을 공유한다.
Redis Cluster는 여러 노드에 자동적인 데이터 분산을 하고, 일부 노드가 실패 혹은 통신 단절에도 계속 운영되는 가용성을 제공한다. 또한 고성능을 보장하면서도 선형 확장성을 제공한다.
2.1. Redis Cluster 특징
full-mesh 구조로 통신하며 cluster bus라는 추가 채널(port)을 사용한다. hash slot을 사용한 키를 관리하고, multi key 명령어는 제한됐다. 또한 클라이언트는 모든 노드에 접속이 가능하고, DB0만 사용이 가능하다.
희한하게 gossip 프로토콜을 사용하는데 gossip 프로토콜은 마치 소문이 퍼지는 것처럼 통신의 개수를 줄이는 프로토콜이다.
2.2. Sentinel과 차이점
클러스트는 Sentinel이랑 비슷하지만 결국 싱글마스터로 작동한다는 차이점이 있다. Sentinel은 단순하고 소규모 시스템의 HA가 필요할 때 선택한다.
클러스터는 데이터 분산에 샤딩을 사용하고, 자동 장애조치를 위해 모니터링 노드(Sentinel)를 추가 배치할 필요가 없다. 또한 multi key 사용이 제한된다.
3. 데이터 분산과 Key 관리
3.1. 데이터 분산
데이터를 분산하려면 기준이 필요하다. 특정 key의 값이 어느 노드(shard)에 속할지 결정하는 메커니즘이 있어야 한다. 보통 분산 시스템에서 해싱이 사용된다.
단순 해싱으로는 노드 개수가 변할 때 모든 매핑이 새로 계산해야 하는 문제가 있다. 이를 해결하기 위해 Hash Slot이 있다.
Redis는 16384개의 hash slot으로 key 공간을 나누어 관리한다. 각 키는 CRC16 해싱 후에 16384로 modulo 연산을 하여 hash slot에 매핑시킨다. hash slot은 각 노드들에 나누어 분배된다.
3.2. 클라이언트의 데이터 접근
한 번 매핑을 만들면 보통 바뀌는 일이 없다. 클러스터 노드는 요청 key에 해당 노드로 자동 redirect를 해주지 않는다.
MOVED 에러를 받으면 해당 노드로 다시 요청해야 한다. 담당 slot이 아니면 클라이언트는 알맞은 노드로 재시도할 수 있다.
4. 성능과 가용성
클라이언트가 MOVED 에러에 재요청을 해야 할 때, 클라이언트는 key-node 맵을 캐싱하여 대부분의 경우 발생하지 않는다. 클라이언트는 단일 Redis 인스턴스를 이용할 때와 같은 성능으로 이용이 가능하다. 대신 분산 시스템에서 성능은 데이터 일관성과 trade-off가 있다. Redis Cluster는 고성능의 확장성을 제공하면서도 일정 수준의 안정성과 가용성을 유지하는 것을 목표로 설계됐다.
4.1. 데이터 일관성
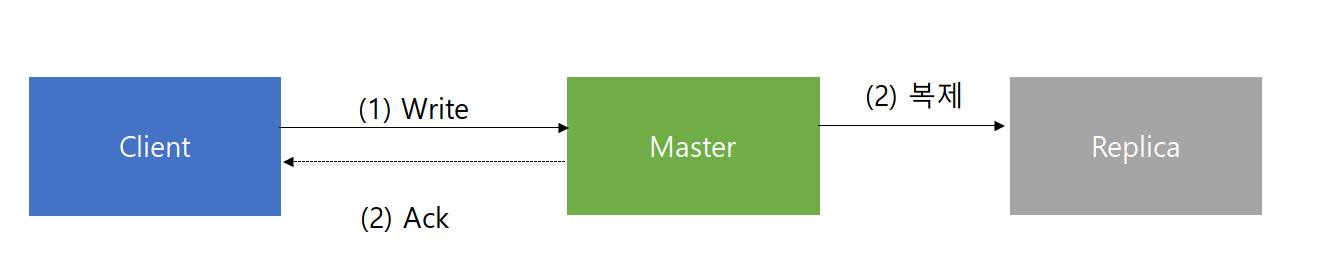
강한 일관성을 제공하지 않는다. 높은 성능을 위해 비동기 복제를 하기 때문이다.
Ack와 복제는 순서가 정해지지 않아서 복제 전에 master가 죽으면 데이터가 유실된다.
4.2. 가용성 - auto failover
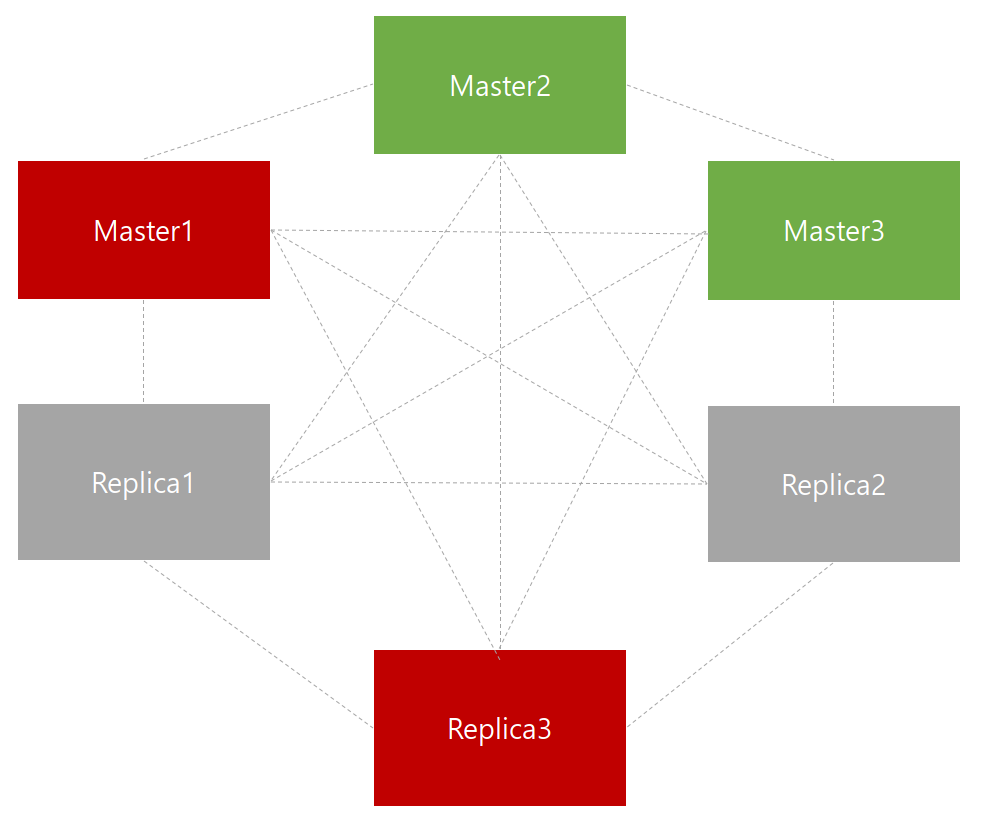
일부 노드가 실패해도 다수의 master가 남아있고, 사라진 master의 replica가 있다면 클러스터는 failover 되어 가용한 상태가 된다.
노드의 timeout동안 다수의 master와 통신하지 못한 master는 스스로 error가 돼서 write 요청을 받지 않는다.
예시로 master1과 replica2가 죽으면 2/3의 master가 남았고, master1이 커버하던 hash slot은 replica1이 master로 승격되어 커버할 수 있다.
4.3. 가용성 - replica migration

replica가 다른 master로 migrate해서 가용성을 높인다.
예시로 master3은 replica 1개를 빼도 1개가 남기에 replica 3-2는 다른 master로 migrate 가능하다.
5. 클러스터 제약 사항
5.1. DB0만 사용 가능
Redis는 한 인스턴스에 여러 DB(Multi DB)를 가질 수 있으며 default는 16이다.
Mutli DB는 용도별로 분리하여 관리를 쉽게 하는 목적이다. 근데 클러스트에서는 Multi DB를 사용할 수 없고 DB0로 고정된다.
5.2. Multi key operation 사용 제약
MSET 같은 multi key 오퍼레이션은 기본적으로 사용할 수 없다. key들이 각각 다른 노드에 저장되기 때문이다. 다만 같은 노드 안에 속한 key들은 multi-key operation이 가능하다.
hash tags 기능을 사용하면 여러 key들을 같은 hash slot에 속하게 할 수 있다.
MSET {user:a}:age 20 {user:a}:city seoulhash tags는 위처럼 key 값 중 {} 안에 들어간 문자열에만 해싱을 수행하는 원리이다.
5.3. 클라이언트 구현 강제
- 클라이언트는 클러스터의 모든 노드에 접속해야 한다.
- MOVED 에러에 대응하기 위해 클라이언트의 redirect 기능을 구현해야 한다.
- 클라이언트 라이브러리가 없는 환경이 있을 수 있기에, 이 경우 대처가 어렵다.
6. 클러스터 구성하기(구현)
6.1. 클러스터 설정 파일
- cluster-enabled <yes/no>: 클러스터 모드로 실행할지 여부를 결정
- cluster-config-file <filename>: 해당 노드의 클러스터 유지를 위한 설정을 저장하는 파일. 사용자가 수정하지 않는다.
- cluster-node-timeout <milliseconds>
- 특정 노드가 정상이 아닌 것으로 판단하는 기준 시간
- 이 시간동안 감지되지 않은 master는 replica에 의해 failover가 이뤄진다.
- cluster-replica-validity-factore <factor>
- master와 통신이 오래된 replica가 failover를 수행하지 않게 하기 위한 설정
- (cluster-node-timeout * factor)만큼 master와 통신이 없으면 replica는 failover 대상에서 제외
- cluster-migration-barrier <count>
- 한 master가 유지하는 최소 replica 수
- 개수를 충족하는 선에서 일부 replica는 replica를 가지지 않는 master의 replica로 migrate 될 수 있다.
- cluster-require-full-coverage <yes/no>
- 일부 hash slot이 커버되지 않는 경우에 write 요청을 받지 않을지 여부
- no로 설정 시에 일부 노드에 장애가 생겨서 해당 hash slot이 정상 작동하지 않더라도 나머지 hash slot에 작동할 수 있다.
- cluster-allow-reads-when-down <yes/no>
- 클러스터가 정상이 아닐 때 read 요청을 받을지 여부
- 어플리케이션에서 read의 일관성이 중요치 않는 경우 yes로 설정할 수 있다.
6.2. 클러스터 구성
Redis 설치해보자 (mac 환경)

6개의 노드들을 설정할 거다.

Conf => 클러스터 설정.

클러스터 모드로 포트는 7000번


이런 식으로계속 띄어준다.
7000번부터 7005번까지

이런 식으로 노드들을나열하고, replicas가 몇 개인지 설정할 수 있다.
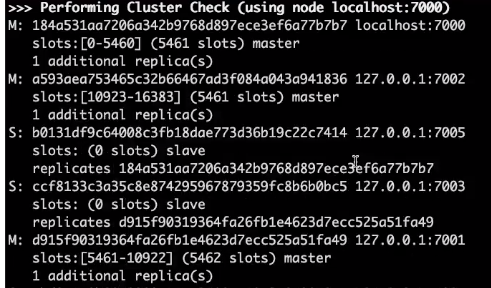
이렇게 노드 정보들이 나온다.
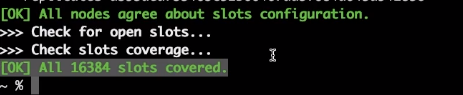
이제 클러스터를 사용해보자
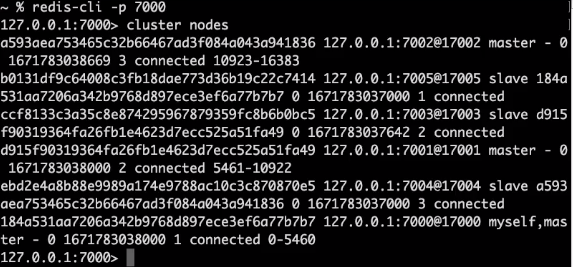
클러스터 정보를 확인 가능하다.
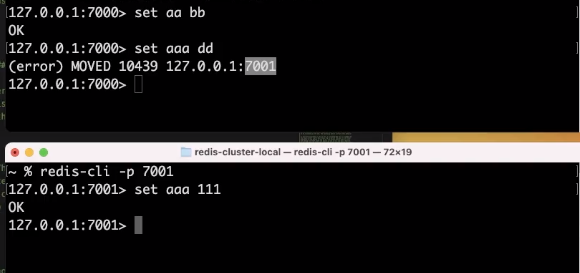
Aaa가 들어가지 않은 이유는 7001번 포트에서 담당한다는 뜻이다.

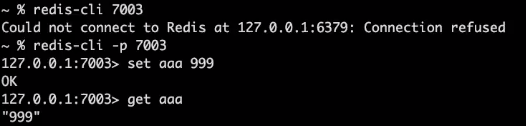
페일오버가 발생해서 7001번이 담당하던 것을 7003번이 담당한다.
노드들을 더 만들어주면

7006번으로 실행.

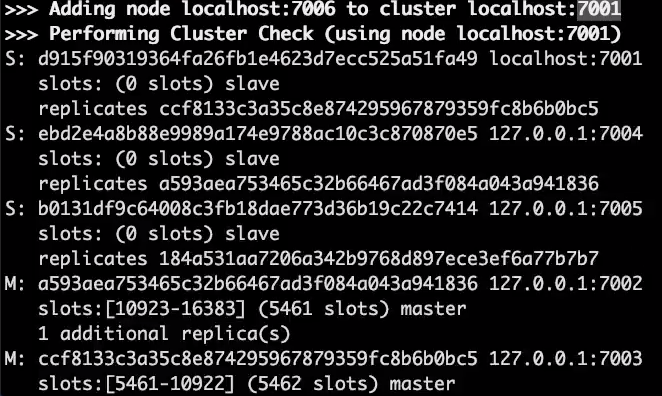

노드가 추가돼서 7개가 됐다.
이제 replica를 만들어보자.
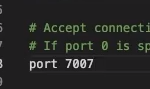
클러스터 설정을 열어주고, 포트는 7007로 설정하자.
실행을 해주면

Slave 옵션을 주면 master slave 형태로 구현.

7006번의 replica가 된 걸 확인할 수 있다.
6.3. Spring을 이용한 클러스터
application.yml 파일에

Reids의 Ip와 port를 컴마를 기준으로 넣는다.
다양한 클러스터에 들어왔는지 확인하려고 테스트 코드를 작성해보자.
public class test{
@Autowired
RedisTemplate redisTemplate;
String dummyValue = "banana";
@Test
void setValues(){
ValueOperations<String, String> ops = redisTemplate.opsForValue();
for(int i=0; i<1000;i++){
String key = String.format("name:%d",i);
ops.set(key, dummyValue);
}
}
}

Redis를 확인해 보면 숫자에 따라서 달라진다.
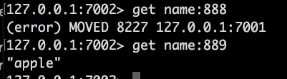
7002번을 죽여보면?

Fail-over가 발생한다.

7004번에서 master로 서비스 하는 것을 볼 수 있다.
그러면 데이터가 잘 있는지 확인 테스트를 써보면?
public class test{
@Autowired
RedisTemplate redisTemplate;
String dummyValue = "banana";
@Test
void setValues(){
ValueOperations<String, String> ops = redisTemplate.opsForValue();
for(int i=0; i<1000;i++){
String key = String.format("name:%d",i);
String value = ops.set(key, dummyValue);
assertEquals(value,dummyValue);
}
}
}


이렇게 설정 파일만 달라지고, 코드상 변경은 없었다.
스프링이 제공하는 Redis 라이브러리가 잘돼있고, 실제 어플리케이션이 동작하는 방식에는 영향을 끼치기 않기 때문이다.
'DB > Redis' 카테고리의 다른 글
| Redis 성능 튜닝 (0) | 2023.08.18 |
|---|---|
| Redis 백업과 장애 복구 (0) | 2023.08.14 |
| Pub/Sub 패턴으로 채팅방 구현 (0) | 2023.08.11 |
| Sorted Sets으로 리더보드 구현 (0) | 2023.08.11 |
| Redis로 캐시 레이어 구현 (0) | 2023.08.11 |



